DFA File Format
A .dfa file represents a deterministic finite automaton (DFA)
together with some optional input data.
You can use the
cs241.dfa tool
to check the syntax of these files and to process the
strings in the input data with the DFA:
$ cs241.dfa < input.dfa
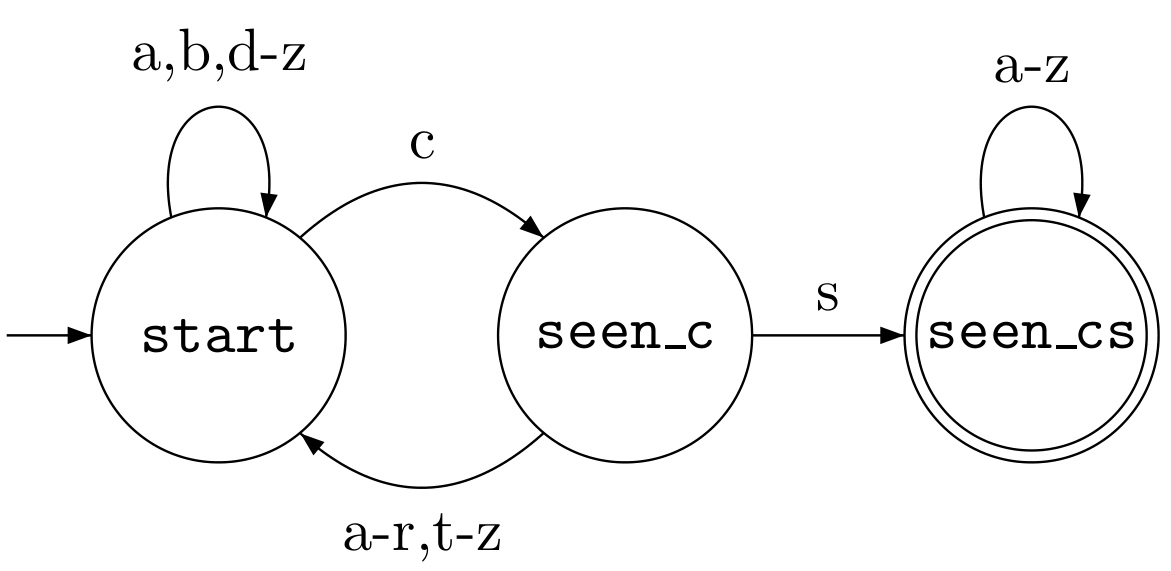
Here is an example of a DFA file for
a DFA that recognizes strings over
the alphabet {a, b, ..., z}
that contain cs.
The text in italics is not part of the file,
and is just there to describe how the file works.
.ALPHABET
a-b d-r t-z
c s
.STATES
start
seen_c
seen_cs!
.TRANSITIONS
start a b d-z start
start c seen_c
seen_c a b d-r t-z start
seen_c c seen_c
seen_c s seen_cs
seen_cs a-z seen_cs
.INPUT
hellocsstudents
.EMPTY
lyrics
cstwofourone bstwofournone ccs
|
character ranges can be specified
or characters can be listed individually
first state listed is the initial state
! marks a state as accepting
loop at 'start' on a, b, and d-z
transition from 'start' to 'seen_c' on c
this special keyword is treated as the empty string
can list multiple inputs on one line
|
|
For this file, the output of cs241.dfa is:
$ cs241.dfa < input.dfa
hellocsstudents true
.EMPTY false
lyrics true
cstwofourone true
bstwofournone false
ccs true
The output indicates which input strings were accepted by the DFA.
Formal Specification
The DFA is encoded in three
sections (alphabet, states, transitions)
and then the input is encoded in a fourth section.
-
All sections must be present in the file,
and the sections must be in the specified order: alphabet, states,
transitions, input.
-
The header for the input section must be
present, even if no input is provided.
-
The alphabet section consists of a header line containing
the string
.ALPHABET, followed by a sequence of
characters or ranges, each separated by whitespace:
-
A character is a single printable, non-whitespace
ASCII character (codes 0x21 to 0x7e).
- A range is two characters separated by a
hyphen
- (ASCII 0x2D), and represents the
range of ASCII characters whose codes are between
the first character and second character (inclusive).
-
The states section consists of a header line containing
the string
.STATE, followed by a sequence of
whitespace-separated non-empty strings representing state names.
-
The first string in the sequence is the initial state.
-
Adding an exclamation mark at the end of a state name
marks it as an accepting state.
-
The transitions section consists of a header line containing
the string
.TRANSITIONS, followed by a sequence of
lines representing transition collections.
A transition collection has three parts, each separated by
(non-newline) whitespace:
-
First is a state name for the from-state.
-
Next is a collection of transition symbols,
specified as a whitespace-separated sequence of
characters or ranges. All the symbols
described by the characters or ranges must
be present in the alphabet.
-
The last string on the line is a state name
for the to-state.
The meaning of a transition collection is: for each symbol in the
transition symbols, there is a transition from
the from-state to the to-state on that symbol.
Nondeterministic transitions (multiple transitions for the
same state-symbol pair) are not allowed.
It is not necessary to specify a transition for
every state-symbol pair.
-
The input section consists of a header line containing
the string
.INPUT. Following this is input data
which can be used by programs that read DFA files. The format
and interpretation of this data depends on the program:
-
The
cs241.dfa tool
will interpret the input
data as a series of whitespace-separated strings to run
through the DFA using the DFA recognition algorithm.
It will print each string followed by true
(if the string was accepted) or false
(if it was not accepted).
It will treat the special keyword .EMPTY
as the empty string.
-
However, a scanner might interpret this section
differently, as one long piece of input to scan into tokens.
Clarifications and Limitations
-
Alphabet symbols can only be single ASCII characters. Symbols composed of
multiple characters are not supported.
-
Whitespace characters are not supported as alphabet symbols, so you cannot
use these DFAs to describe a language where strings can have spaces
or newlines.
-
The exclamation mark (!) used to indicate whether a state is accepting is
not part of the state name. This means you cannot have a non-accepting
state whose name ends with an exclamation mark.
-
Exception to the above: A state name that consists of single exclamation mark
will be treated as a non-accepting state with name "!".
-
You can have accepting states that end with an exclamation mark if you
include two exclamation marks. For example,
bang!! would
correspond to a state named bang! that is accepting.
- The string
.TRANSITIONS cannot be used as a state name, since
it marks the end of the states section.
- The string
.INPUT can technically be used as a state name,
but you cannot use this state name in the transitions section as it marks
the end of the transitions section.
-
This file format is for DFAs only. It cannot be used to describe
NFAs and ε-transitions are not supported.
Augmentation for SMM
The cs241.SMM tool accepts a slightly modified version of the above format, with two additions.
- The space and newline characters are allowed in the alphabet and transition table. They are represented with the special sequences
.SPACE and .NEWLINE respectively.
- The DFA file does not require a
.INPUT section (and you should probably not have one as cs241.SMM reads input from this section if present).