Clean Architecture

Martin, Robert C. Clean Architecture: A Craftsman’s Guide to Software Structure and Design. Prentice Hall, 2017
Building upon the success of best-sellers The Clean Coder and Clean Code, legendary software craftsman Robert C. “Uncle Bob” Martin shows how to bring greater professionalism and discipline to application architecture and design.
Part I: Introduction
It doesn’t take a huge amount of knowledge and skill to get a program working. Kids in high school do it all the time… Getting it right is another matter entirely. Getting software right is hard… When software is done right, it required a fraction of the human resources to create and maintain. Changes are simple and rapid. Defects are few and far betweeen. Effort is minimized, and functionality and flexibility are maximized.
For Martin, the indicator that software is well-designed is that it can be extended, scaled and maintained with minimal effort.
Chapter 1: What is Design and Architecture?
Architecture is often characterized as the “high-level details” that are divorced from the design i.e. “low-level details”. These should be seen as part of a continuum that includes both low-level and high-level design details, which coexist in describing how your system works.
The Goal of Architecture
“The measure of design quality is simply the measure of the effort required to meet the needs of the customer. If that effort is low, and stays low throughout the lifetime of the system, the design is good. ”
Martin leans pretty heavily on this idea – “good design” is that which requires the “least effort to maintain”. I agree that “ease of maintainence” is a great quality to have, but I can think of many more that we’re ignoring e.g., fitness to purpose, scalability, extensibility.
To support his position, he introduces a case study for a “market leading software product company”, showing the growth of their engineering over an eight year period, relative to their product size (measured in KLOC) over the same period.


His characterizes this as a “remarkable change in productivity”, and states that “clearly something is wrong here”. If you think of software development as the “race to generate source code” then maybe this would hold true…but this isn’t how software development works.
Imagine a sculptor, working a large piece. Now imagine measuring their productivity as “amount of stone removed per day”. We would see a similar graph: productivity is huge on the first day, but quickly declines as they continue working. By the end, they are removing smaller and smaller amounts of stone as they refine their work.
I don’t think anyone would accuse the sculptor of being less productive over time; it’s a meaningless phrase, since that’s not how sculpting works. The process is defined by successively smaller refinements to a body of work.
Software works in much the same way. You should see large, structural changes at the beginning, and successively smaller refinements to that code over time.
I would argue the opposite position from Martin: seeing large changes over time to the same parts of code is more likely to be an indicator of problems - either in the problem definition (i.e. you were “building the wrong thing”) or in implementation (i.e. you “made a mistake”).
- “Slow and steady wins the race.”
- “The race is not to the swift, nor the battle to the strong.”
- “The more haste, the less speed.”
He seems to suggest that the productivity issues that he has identified fall out of “going too fast”. This may be true, but he’s provided no evidence. I’m not convinced that we have a productivity crisis, and that execution speed is the obvious cause of anything he has identified.
Chapter 2: A Tale of Two Values
He characterizes software systems as adding value to a customer in two ways:
- Delivering functionality (what he calls “behaviour”), and
- Architecting a system.
He argues that we should be delivering functionality, but doing so on a way that ensures that “when stakeholders change their minds about a feature, that change should be simple and easy to make”. In other words, architectures should be “shape agnostic [as] practical”. I agree that this elasticity of software is a valuable property, and we should be designing systems with some flexibility in mind.
However, he then makes the bold claim that it’s “more important for the software system to be easy to change than to work”. His logic is based on the claim (paraphrased) that:
- A flawed system can always be made to work, provided it’s easy to change.
- A program that cannot change will become useless when the requirements change. Therefore, the fact that it works now is irrelevant.
He justifies this due to the possibility of creating systems that are “practically impossible to change”, completly ignoring the fact that it’s also possible to create systems that completely fail at their intended function. Neither situation is desireable.
I fundamentally disagree with Martin here. A system that fails to accomplish it’s purpose is worse than useless: it’s a waste of time, effort and money. Deliver a sailbat when you’ve been asked to build a racing car and you will be instantly fired (and sued out of business) – it doesn’t matter how well you designed it.
Should we prioritize architecture? Certainly it’s important, but architecture always has to serve the requirements of the product.
Fight for the Architecture
As architects, we must fight for our position i.e. architecture over features.
What does that mean exactly? Other stakeholders may not value a flexible architecture as much as the developers, so you need to be prepared to fight for the long-term health of your software.
Part II: Starting with the Bricks: Programming Paradigms
Chapter 3: Paradigm Overview
This section examines the way that we think about software structure - in particular, programming paradigms. He includes three main paradigms and reviews them.
Chapter 4: Structured Programming
Discovered by Edsger Dijkstra in 1968, who suggested that unrestrainted use of of jump statements in code was harmful to program structure. He introduced familiair control flow constructs like if/then/else, and do/while.
“Dijkstra knew that those control structures, when combined with sequential execution, were special. They had been identified two years before by Böhm and Jacopini, who proved that all programs can be constructed from just three structures:
sequence,selection, anditeration.”
Dijkstra was interested in applying mathematical rigor to software and algorithms; these principles were useful in leading us to more predictable computation. They also made software more modular and human-understandable, which were major factors in allowing us to design and implement larger systems.
Structured programming imposes discipline on direct transfer of control. – Martin
Chapter 5: Object-Oriented Programming
Discovered in 1966 by Ole Johan Dahl and Kristen Nygaard. They realized that a function call frame stack in ALGOL could be moved into heap memory, allowing it to persist after the function returned. The function became a constructor for a class variables becames instance variables, and nested functions became methods.
OO programming is a way of modeling the world using software constructs that are analogous to real-world objects. Software classes describe how a particular objects works (behaviour) along with any state that it needs to manage for this behaviour to work (data).
We often refer to three core concepts in OO programming:
- Encapsulation: the class “protects” its data from direct manipulation by external entities.
- Inheritance: the ability to describe a relationship between two classes, where a
childclass provides a specialized version of aparentclass’s behaviour. - Polymorphism: different types share a common interface, and can be interchanged with one another.
Martin spends considerable time demonstrating how these can all be implemented in C, for some strange reason.
Object-oriented programming imposes discipline on indirect transfer of control. – Martin
Chapter 6: Functional Programming
Functional programming is based on lambda-calculus invented by Alonzo Church in 1936, which was used in the creation of LISP by John McCarthy in 1958. The foundational principle of functional programming, according to Martin, is immutability i.e. the inability to modify variables.
To Martin, “All race conditions, deadlock conditions, and concurrent update problems are due to mutable variables. You cannot have a race condition or a concurrent update problem if no variable is ever updated.”
Functional programming imposes discipline upon assignment.
In summary, each of these paradigms removes some capabilities or constraints the programmer in a way that leads to “better code”. Marin doesn’t think there’s more to remove, and that these three are likely the last paradigms we’ll see.
How do they apply? At a macro-level:
Polymorphismis used to cross architectural boundaries,Functional programmingimposes disciplines on storage and access to data, andStructured programmingis the algorithmic foundation to our modules.
What we have learned over the last half-century is what not to do… The rules of software are the same today as they were in 1946, when Alan Turing wrote the very first code that would execute in an electronic computer. Software—the stuff of computer programs—is composed of
sequence,selection,iteration, andindirection. Nothing more. Nothing less. – Martin”
Part III: Design Principles
Martin published the SOLID principles in the early 2000s. They are intended to provide guidelines on how to arrange functions and data structures into classes.
The goals of SOLID are the creation of mid-level software structures that:
- Tolerate change,
- Are easy to understand, and
- Are the basis of components that can be used in many software systems.
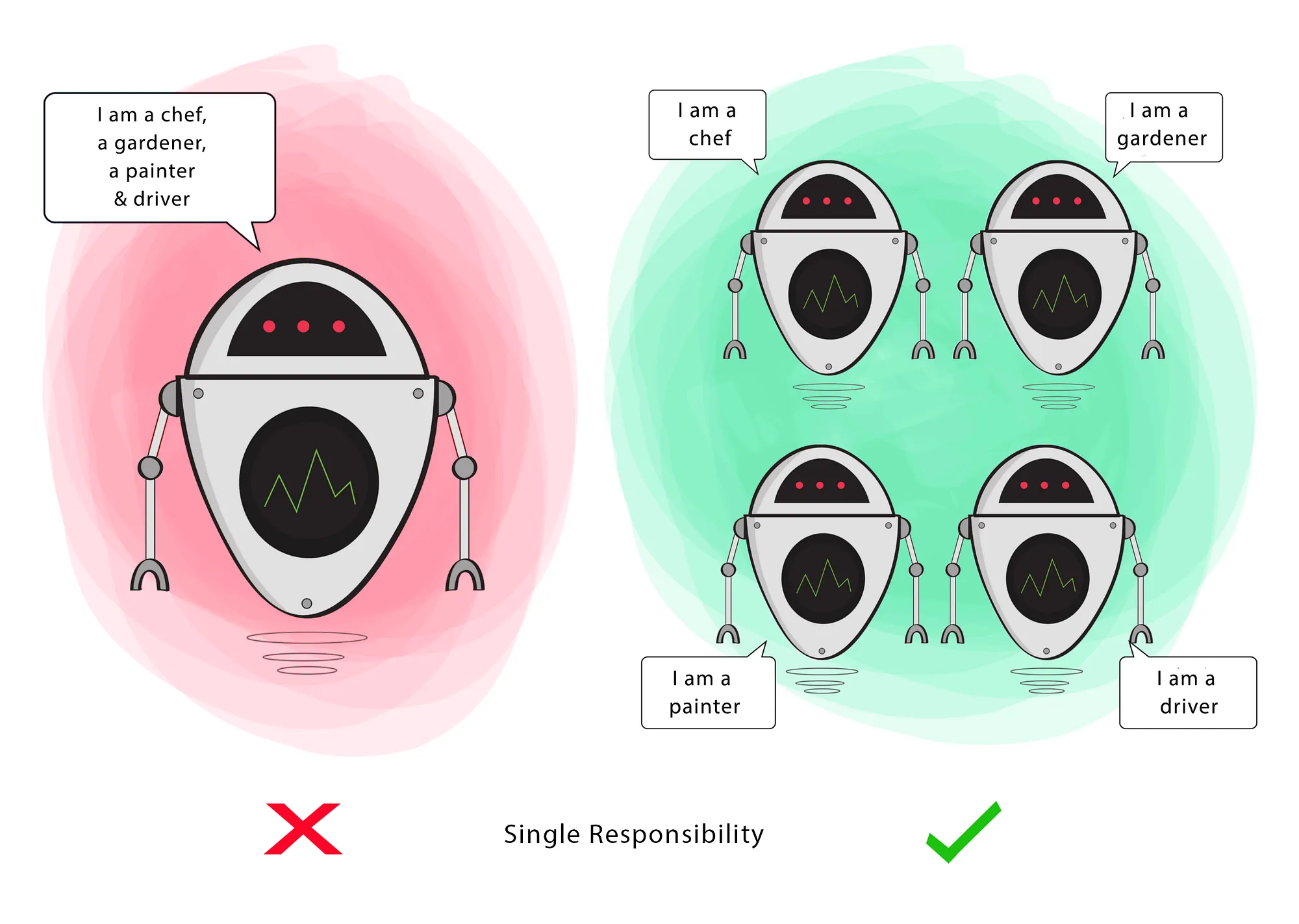
class does not imply that these principles are applicable only to object-oriented software”. This feels a little revisionist, although I agree that we should be looking to apply design concepts beyond OO/classes.1. Single Responsibility
“A module should be responsible to one, and only one, user or stakeholder.” – Martin (2002)
“An active corollary to Conway’s law: The best structure for a software system is heavily influenced by the social structure of the organization that uses it so that each software module has one, and only one, reason to change.” – Martin (2019)
The Single Responsibility Principle (SRP) states that we want classes to do a single thing. This is meant to ensure that are classes are focused, but also to reduce pressure to expand or change that class. In other words:
- A class has responsibility over a single functionality.
- There is only one single reason for a class to change.
- There should only be one “driver” of change for a module.
2. Open-Closed Principle
“A software artifact should be open for extension but closed for modification. In other words, the behaviour of a software artifact ought to be extensible, without having to modify that artifact.” – Bertrand Meyers (1988)
For software systems to be easy to change, they must be designed to allow the behavior of those systems to be changed by adding new code, rather than modifying existing code.
This principle is often used to champion subclassing as the primary form of code reuse.

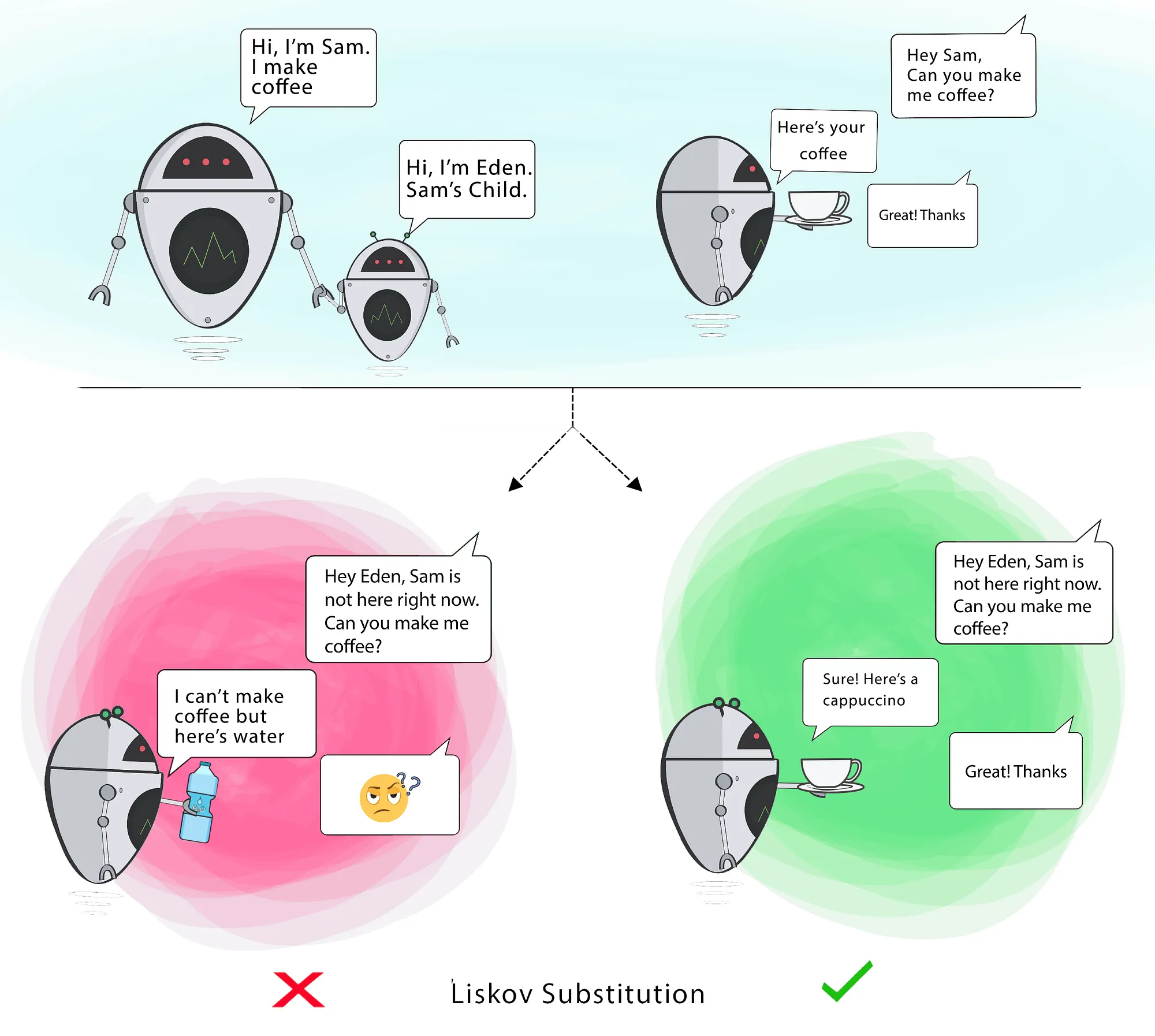
3. Liskov-Substitution Principle
“If for each object o1 of type S there is an object o2 of type T such that for all programs P defined in terms of T, the behaviour of P is unchanged when o1 is substituted for o2, then S is a subtype of T.” – Barbara Liskov (1988)
To build software systems from interchangeable parts, those parts must adhere to a contract that allows those parts to be substituted one for another.
in OO programming, it should be possible to substitute a derived class for a base class, since the derived class should still be capable of all the base class functionality. In other words, a child should always be able to substitute for its parent.
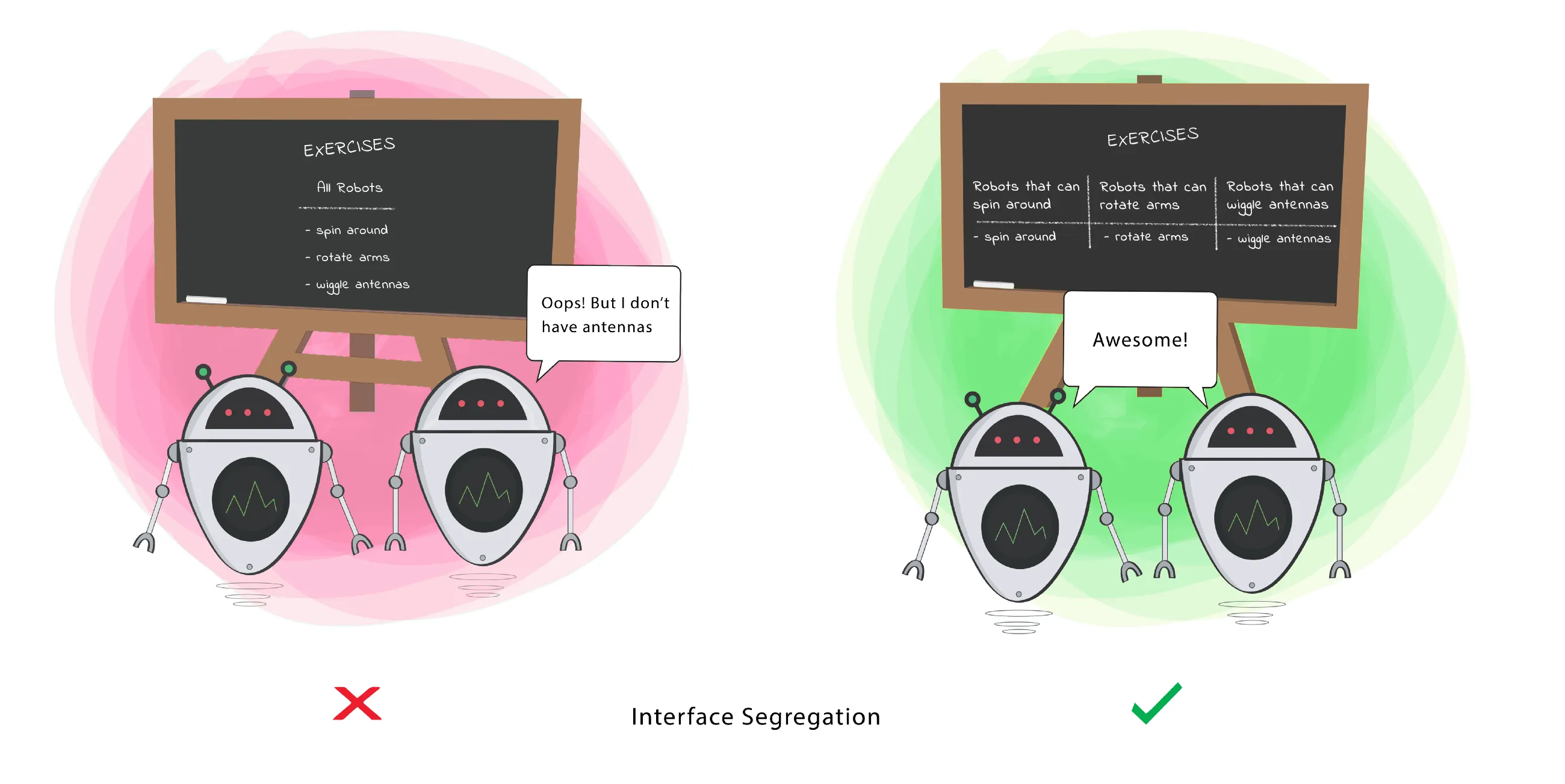
4. Interface Segregation Principle
“This principle advises software designers to avoid depending on things that they don’t use. - Martin (2019)
Also described as “program to an interface, not an implementation.” Never make assumptions about an implementation. Allow flexibility, and the ability to substitute other valid implementations that meet the functional needs.
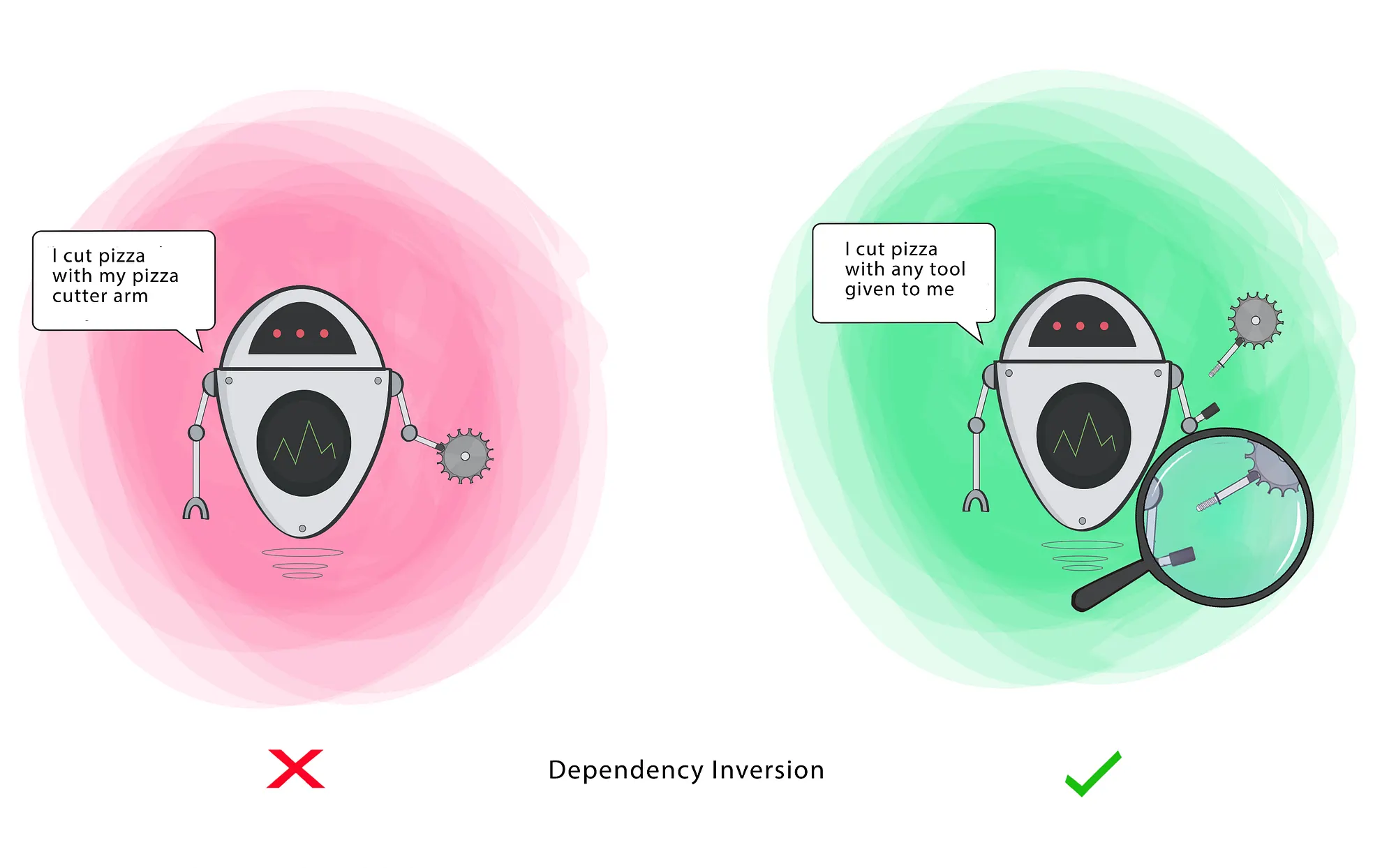
5. Dependency Inversion Principle
The most flexible systems are those in which source code dependencies refer to abstractions (interfaces) rather than concretions (implementations). This reduces the dependency between these two classes.
- High-level modules should not import from low-level modules. Both should depend on abstractions (e.g., interfaces).
- Abstractions should not depend on details. Details (concrete implementations) should depend on abstractions.
Part IV: Component Principles
“If the SOLID principles tell us how to arrange the bricks into walls and rooms, then the component principles tell us how to arrange the rooms into buildings. Large software systems, like large buildings, are built out of smaller components.”
Chapter 12: Components
“Components are the units of deployment. They are the smallest entities that can be deployed as part of a system. In Java, they are jar files. In Ruby, they are gem files. In .Net, they are DLLs. In compiled languages, they are aggregations of binary files. In interpreted languages, they are aggregations of source files. ”
Chapter 22: The Clean Architecture
Clean architecture is an architectural style commonly used with modern mobile and desktop applications, which generalizes the layered architectural model. Clean architecture is derived from other modern approaches to architecting systems (described in Martin 2017). These include:
- Hexagonal Architecture, developed by Alistair Cockburn, and adopted by Steve Freeman
- DCI from James Coplien and Trygve Reenskaug
- BCE, introduced by Ivar Jacobson

Clean architecture (blog.cleancoder.com)
This diagram represents different layers of software, each with their own responsibilities. The following guidelines help determine how layers interrelate.
Dependency rule
The dependency rule describes relationship between layers: nothing in the inner circle can know about the outer circles. Dependencies are only allowed to go from the outside to the inside; outside classes can only refer to the same or a more inner layer.
This means that the domain objects (innermost layer) don’t directly reference or use any external frameworks (outermost layer). External frameworks and libraries are pushed to the outside of the architecture to reduce coupling to these frameworks! This allows for greater flexibility later, if we need to replace one of them, e.g., switching to a different database implementation.
Layers
A clean architecture is like an onion: layers spread out from the core entities. Here’s what each layer does.
Entities (domain models)
These are data classes that reflect your problem domain, e.g. classes like Customer, Invoice, Journal, Note. These are the core classes in your application and unlikely to change from external pressures or from the addition of features (which is why we can have everything else depend on them!)
What differentiates these from use cases is that enterprise entities can span components or services. If you are building a single application, then these are the core data classes.
Use cases (application)
These are application-specific classes that build on the core entities. They facilitate data flow to and from the entities. This is also where you would implement core application logic (that wasn’t handled by the outermost layers like the UI framework).
Controllers (infrastructure)
These are interface adapters that map data from the entities or use cases, to a format that is required by the external layers. For instance, this layer might add the model-view-controller abstraction for the user interface, or convert data from classes into a format that is suitable for storing in a database.
Interfaces (frameworks)
These are frameworks that provide services. Typically, these services are provided for you and you merely need to interface with them.
This design addresses our earlier concerns by providing a separation of concerns between each layer. This allows us to swap databases, user interfaces and other layers as needed.
Dependency inversion
The diagram above shows flow-of-control: which classes call into which other classes. In this case, outside classes call into inner classes. This also represents the source code dependencies.
The way we handle source code dependencies is with dependency inversion. This is meant to keep maintain the distance between high and low level modules:
- High-level modules should not import anything from low-level modules. Both should depend on abstractions (e.g., interfaces).
- Abstractions should not depend on details. Details (concrete implementations) should depend on abstractions.
We will see examples of using this architecture when setting up our edge dependencies, e.g., database, user interface.
Why do we do this?
- It reduces coupling by carefully controlling dependencies.
- It encourages cohesion since layers have a specific responsibility.
- External dependencies are pushed to the outermost layers, which reduces dependencies on specific frameworks or specific implementation dependendies. e.g., it is easier to swap out user interface frameworks, or keep your application decoupled from any specific implementation.
- Reducing dependencies makes it possible to test classes at each layer independently! We’ll see this when we discuss unit testing.
In some ways, a clean architecture can also be described as a generalized layered architecture.
