Replication is a process of maintaining a defined set of data in more than one location. It involves copying designated changes from one location (a source) to another (a target), and synchronizing the data in both locations. The source and target can be in logical servers (such as a DB2 database or a DB2 for OS/390 subsystem or data-sharing group) that are on the same machine or on different machines in a distributed network.
A number of IBM products enable you to replicate data. The product that is the focus of this book--DB2 DataPropagator--is a replication product for relational data. You can use it to replicate changes between any DB2 relational databases. You can also use it with other IBM products (such as DB2 DataJoiner and IMS DataPropagator) or non-IBM products (such as Microsoft SQL Server and Sybase SQL Server) to replicate data between a growing number of database products--both relational and nonrelational.
The replication environment that you need depends on when you want data updated and how you want transactions handled. You have the flexibility to choose the locations of the replication components to maximize the efficiency of your replication environment.
Before you go to Chapter 2 and begin designing your replication environment, read this chapter to familiarize yourself with the DB2 replication components and their associated concepts.
DB2 DataPropagator consists of three main components: administration interfaces, change-capture mechanisms, and the Apply program.
This section describes the control tables that manage replication requests, the logical servers that contain the replication components, as well as the main components (administration interfaces, change-capture mechanisms, and the Apply program) and how they communicate with each other.
The replication components use control tables to communicate with each other and to manage replication tasks (such as managing replication sources and targets, capturing changes, replicating changes, and tracking how many changes are replicated and how many remain to be done).
The change-capture mechanisms use the following control tables: register table, unit-of-work table, pruning control table, prune lock table, critical section table, warm start table, tuning parameters table, and change data tables. For additional control tables that are platform-specific, see Table structures.
The Apply program uses the following control tables: Apply trail table, critical section table, pruning control table, prune lock table, register table, subscription set table, subscription statements table, subscription events table, subscription-targets-member table, subscription columns table, unit-of-work table, and change data tables.
All the replication components reside on a logical server. In this book, logical servers refer to databases, not to servers in the client/server sense. For the OS/390 operating system, logical servers are equivalent to subsystems or data-sharing groups (that is, the domain of a single database catalog). There are three types of logical servers:
The Apply program can reside on any of the logical servers in the network. It uses distributed DB2 technology to connect to the control, source, and target servers.
Each Apply program is associated with one control server, which you specify when you start the Apply program. Multiple Apply programs can share a control server.
You use the administration interfaces to create control tables, which store your replication criteria. Two user interfaces are available: DB2 Control Center and DataJoiner Replication Administration (DJRA).
The DB2 Control Center is a database administration tool that you can use to administer the replication of data between DB2 servers. It automates many initialization functions, such as creating target tables and control tables when you specify target information.
You can use the Control Center to perform the following administration tasks for replication:
The DataJoiner Replication Administration (DJRA) tool is a database administration tool that you can use to perform various replication administration tasks. You can use this tool for DB2-to-DB2 replication; however, you must use it if your replication environment includes non-IBM databases.
You can use DJRA to perform the following administration tasks:
The DB2 data replication solution offers these mechanisms for capturing data:
The following sections describe the Capture program and triggers. For more information about how changes are replicated in Microsoft Access and Microsoft Jet databases, see Using DB2 DataPropagator for Microsoft Jet.
When the source is a DB2 table, the Capture program captures changes that are made to the source. The Capture program uses the database log 8 to capture changes made to the source database and stores them temporarily in tables.
The Capture program runs at the source server. Typically it runs continuously, but you can stop it while running utilities or modifying replication sources.
For instructions on using the Capture program, see Operations.
When the source table is in a non-IBM database (other than Teradata, Microsoft Access, and Microsoft Jet), Capture triggers capture changes that are made to the source. Capture triggers are fired when a particular database event (UPDATE, INSERT, DELETE) occurs.
DJRA automatically creates the Capture triggers. These triggers capture the changes made to tables defined as replication sources and store the changes temporarily in tables.
The Apply program reads data directly from source tables or views to initially populate the target table. If the source tables are in a non-IBM database, the Apply program reads the data from a nickname. If you want changes copied, the Apply program reads the changed data that is stored temporarily in tables, and applies the changes to target tables.
The Apply program generally runs at the target server, but it can run at any server in your network that can connect to the source, control, and target servers. Several Apply program instances can run on the same or different servers. Each Apply program can run using the same authorization, different authorization, or as part of a group of Apply programs where each Apply program in the group runs using the same authorization (user ID).
Each Apply program is associated with one control server, which contains the control tables that contain the definitions for the subscription sets. The control tables can be used by more than one instance of the Apply program. For example, if you have one source server and two target servers, you can have separate Apply programs running at each target server. The two apply instances can share the control tables, which will have the specific information related to each Apply instance.
For instructions on using the Apply program, see Administration.
The replication components are independent of each other, so they rely on information that is stored in control tables to communicate with each other. The Capture and Apply programs and the Capture triggers update control tables to indicate the progress of replication and to coordinate the processing of changes.
The replication components communicate differently depending on whether the source server is a DB2 server or a non-IBM server. For replication between DB2 servers, the Capture program captures changes that are made to data in source tables by reading the server log or journal. Then the Capture program places the changes into tables called change data (CD) tables. For non-IBM sources, Capture triggers capture changes and store them in consistent-change-data (CCD) tables.
Each time that the Apply program copies data to the target database, the contents of the target database reflect the changes that were made to the source database. The Apply program works by applying transactions accumulated since the Apply program last ran. The Apply program keeps track of the latest update that it makes to each target.
The Capture program uses some of the control tables to indicate what changes have been made to the source database, and the Apply program uses these control table-values to detect what needs to be copied to the target database.
Important: The Capture program will not capture any information until the Apply program signals it to do so, and the Apply program will not signal the Capture program to start capturing changes until you define a replication source and associated subscription sets. See Performing the initial replication for more information about the steps that you must perform so that the components communicate with each other and replicate changes.
The following process describes how the Apply and Capture programs communicate in a typical replication scenario to ensure data integrity:
Capturing data from a source database
Applying data to a target database
Pruning the tables
DJRA, working through DB2 DataJoiner, creates Capture triggers on non-IBM source tables when you define them as replication sources. Three types of triggers are created on the source table: DELETE, UPDATE, and INSERT. Also, UPDATE triggers are created on the pruning control table and the register synchronization table. The Apply program uses these control tables to detect what needs to be copied to the target database.
The following process describes how the Capture triggers and the Apply program communicate in a typical replication scenario to ensure data integrity:
Capturing data from a source
Applying data to a target
Pruning the tables
This section introduces some of the important concepts of DB2 data replication. You should read the whole section to get a complete overview.
A replication source is a user table or view from which you want data copied. Before you can replicate data, you must define a replication source to describe the information that the change-capture mechanisms will use. When you define a replication source you must specify which columns you want to replicate, and decide whether you want updates treated as UPDATE operations or DELETE and INSERT operations. See Enabling replication logical-partitioning-key support for more information on how to treat updates. In addition, you must decide:
An after-image column contains the value of a data column in a source table after the value in that data column is updated. A before-image column contains the value of a data column in a source table before that data column is updated. When you define a replication source, you can choose to capture only the after-image or both the after-image and the before-image. Your decision will depend both on the way in which you plan to use the data and on the types of tables that you are using.
Before-image columns are useful if your applications require auditing or rollback capability. Some restrictions apply to how you use these columns, and they are discussed later in this book (Replicating before and after images).
The Apply program copies data from the source to the target either by full-refresh only or differential-refresh copying.
During full-refresh only copying, the Apply program performs these tasks:
During differential-refresh copying, the Apply program copies only the changed data to the target table.
Conflict detection pertains only to update-anywhere replication configurations. It is the process of detecting if the same row was updated in the source and target tables during the same replication cycle. With standard conflict detection, the Apply program searches for conflicts in rows that are already captured in the CD tables. With enhanced conflict detection, the Apply program locks all of the target tables, thus ensuring that all changes are considered when checking for conflicts. Row-replica conflict detection applies only to tables that are maintained by DataPropagator for Microsoft Jet; where conflicts are detected on a row-by-row basis instead of a transaction-by-transaction basis.
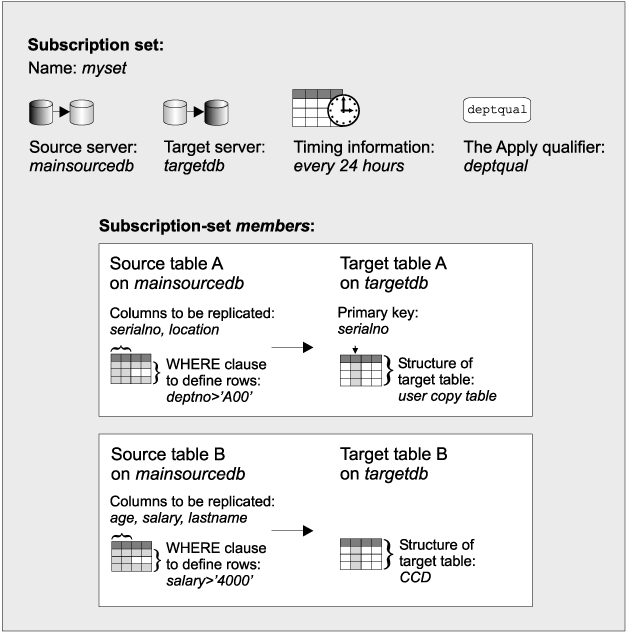
Before you can replicate data from the replication source, you must associate the replication source with the target to which you want the changes replicated. You define this information using subscription sets and subscription-set members. The information that you provide is stored in various replication control tables.
A subscription set contains the attributes of a replication subscription. When you create a subscription set, you define the following attributes:
A subscription set must have one subscription-set member for each target table or view. When you create a subscription-set member, you define the following attributes:
Subscription sets ensure that all subscription-set members are treated alike during replication: either changes are applied to all targets or to none of them. The changed data for all the subscription-set members in a subscription set is replicated to the specified target tables in a single transaction. Subscription sets optimize performance because the target tables in a set are processed in one transaction against the target server. Subscription sets also preserve referential integrity.
Each subscription set is processed by one Apply program; however, each Apply program can process many subscription sets. The relationship between a subscription set and subscription-set members is shown in Figure 1.
Figure 1. Subscription sets and subscription-set members. Example of the relationship between a subscription set and subscription-set members.
|
The Apply qualifier associates an Apply program with one or more subscription sets. You specify a case-sensitive string as the value for the Apply qualifier when you define a subscription set. 10
By using more than one Apply qualifier, you can run more than one instance of the Apply program from a single user ID. The Apply qualifier is used to identify records at the control server that define the work load of an instance of the Apply program; whereas the user ID is for authorization purposes only. For example, assume that you want to replicate data from two source databases to the target tables on your computer. The data in source table A is replicated using full-refresh copying to target table A, and the data in source table B is replicated using differential-refresh copying to target table B. You define two subscription sets (one for table A and one for table B), and you use separate Apply qualifiers to allow two instances of the Apply program to copy the data at different times. You can also define both subscription sets using one Apply qualifier.
You might want to replicate only a subset of your source table, use a simple view to restructure the data from the source table to the target table, or use more complex joins and unions.
You can replicate certain columns or rows from the source table instead of replicating the whole source table. This process, which is sometimes known as table partitioning, is called column subsetting and row subsetting in this book.
Use column subsetting if you want to replicate only a subset of all of the columns from the source. This type of subsetting is appropriate, for example, if some of the columns in the source are very large, such as large objects (LOBs), or if the column data types are not supported by the intended target table.
Use row subsetting if you want to replicate only some of the rows from the source database. For example, when you are replicating data to more than one regional office, you might want to replicate only records that are relevant to that particular regional office. To subset rows, use the WHERE clause when defining the subscription-set member.
Simple views are useful in data warehouse scenarios if you want to restructure copies so that data in target tables is easily queried.
For example, assume that a database contains both a resume table and a photograph table. The human resources department needs one table that contains every employee's resume and photograph. You can create a view that contains both the resume and photograph tables, define that view as a replication source, and create a subscription set to replicate the data from the view to a target table in the human resources database.
Views are also useful for introducing related columns in other tables. You can reference the columns in other tables in the subscription-set member predicates, which facilitates the routing of updates to the appropriate target sites.
You can create and maintain target tables with contents that are joins or unions of existing source tables.
You can use the following types of joins:
You can use joins and unions to manipulate data in the following ways:
When you define a subscription-set member, you must specify the type of target table that you want to use. The following types of tables are available:
The following sections describe the unique characteristics of each type of target table.
These tables are read-only copies of the replication source with no replication control columns added. They look like regular source tables and are a good starting point for replication. They are the most common type of target table.
These tables are read-only copies of the replication source with a timestamp column added. The timestamp column is originally null. When changes are replicated, values are added to indicate the time when updates are made. Use these types of tables if you want to keep track of the time of changes.
These are read-only tables that use SQL column functions (such as SUM and AVG) to compute summaries of the entire contents of the source tables or of the recent changes made to the source table data. Rows are appended to aggregate tables over time. There are two kinds of aggregate tables: base aggregate tables and change aggregate tables.
Base aggregate tables summarize the contents of a source table. Use a base aggregate table to track the state of a source table on a regular basis. For example, assume that you want to know the average number of customers that you have each month. If your source table has a row for each customer, you would average the number of rows in your source table on a monthly basis and store the results in a base aggregate table.
A base aggregate table does not track change information. For example, assume you had an average of 500 customers in January and 500 in February; however, in February you lost two existing customers and gained two new ones. The base aggregate table shows you that you had the same average number of customers in both months, but it does not show the changes that were made during February. If you want to track change information, use a change aggregate table.
Change aggregate tables work with the change data in the control tables, not with the contents of the source table. Use a change aggregate table to track the changes (UPDATE, INSERT, and DELETE operations) made over time. For example, assume that you want to know how many new customers you gained each month (INSERTS) and how many existing customers you lost (DELETES). You would count the changes that are made to the rows in your source table on a monthly basis and store that number in a change aggregate table.
These tables contain data from committed transactions. They also contain an indicator of whether the target table was changed using an INSERT, DELETE, or UPDATE operation. They can contain both the old and new value of the data. Each type of CCD table (local and remote, complete and noncomplete, condensed and noncondensed, internal and external), has a different use. Attributes of CCD tables describes these types, when to use them, and how to define them. You can use the different types of CCD tables to collect and manipulate data in the following ways:
These are the only target tables that your applications can update directly. Changes made to replicas and row-replicas are replicated to the associated source table; the source table in turn replicates the changes to other replicas. Replicas are supported only in DB2 databases. A row-replica table is a special type of replica table for DB2 DataPropagator for Microsoft Jet. Use the replica table types for update-anywhere replication.
You don't actually specify a user table as a target; however, in update-anywhere replication, a user table is automatically a target for the replicas or row-replicas that are associated with it. The user table is the parent of the replica, and its copies are dependent replicas. The parent of the replica receives updates from a dependent replica and, if there are no conflicts detected, it replicates the changes to the other dependent replicas. The parent of the replica is the primary source of data. If there are any update conflicts detected, the contents of the parent of the replica prevail. Typically your applications access the dependent replica tables; however, they connect to the server containing the user table when the replicas are not available.
Synchronous replication delivers updates continually. When a change is made to the source data, it is temporarily stored and forwarded to the target at a later time. A change is committed to the source database only after the change is replicated to the target database. If for some reason the change cannot be replicated to the target database, the change is not made to the source database. This type of replication is also called real-time replication. If your application requires synchronous updates, code your applications to update tables in a single, distributed transaction instead of using the products described in this book.
Asynchronous replication delivers updates in stages. When a change is made to the source data, it is stored temporarily for a preset interval and forwarded to the target at a later time. The interval can be a measure of time (seconds, minutes, hours) or can represent a prescribed event (midnight, or some other time of day). If changes cannot be made to a target database (for example, if the target database is down or the network is down), they are stored and applied later, in the order in which they were made to the source. This type of replication provides many benefits over synchronous replication: better use of network resources, less database contention, and the opportunity to enhance data before it reaches the target database.
DB2 DataPropagator performs asynchronous replication; therefore, changes made to the source are not made immediately to the targets. You can control how frequently the changes are applied to the target by specifying time intervals, events, or both. For environments that have occasionally connected clients, you can replicate data on demand.
This is the simplest method of controlling the timing of replication. To use interval timing, you choose a date and time for the Apply program to start replicating data to the target, and set a time interval that describes how frequently you want the data replicated. When the Apply program stops, it will not start again until the time interval passes. The time interval can be a period of time (from one minute to one year), or it can be continuous. A continuous time interval means that the Apply program starts replication cycles one after the other, with only a few seconds delay in-between (you can control the delay with the start parameter). The intervals that you provide are approximate. The interval actually used by the Apply program depends on the number of updates that the Apply program has to replicate and on the availability of resources (that is, database table, table space).
This is the most precise method of controlling the timing of replication. To use event timing, you specify the name for an event when you define the subscription set. You then set the time when you want that event processed. Optionally, you can set an end-of-period time; the Apply program will not replicate any transactions committed after this time, but will defer their replication until a future date.
You or your application must provide information for event timing. This information is stored in the subscription events table. The Apply program searches the subscription events table for the event name and the associated time and end-of-period information.
You can replicate data on demand by using the ASNSAT command. This command starts the Apply program and, if necessary, it also starts the Capture program. Each program self-terminates after it completes its part of one replication cycle. This command is supported on Windows 32-bit operating systems, and its invocation parameters are described in Replicating on demand (Windows 32-bit operating systems only).
ASNSAT is also used in replication configurations that include occasionally connected systems. For details, see DB2 Universal Database Administering Satellites Guide and Reference.