Concurrency
Using coroutines to manage concurrency.
Programs typically consist of functions, or subroutines, that we call in order to perform some operations. One underlying assumption is that subroutines will run to completion before returning control to the calling function. Subroutines don’t save state between executions, and can be called multiple times to produce a result. For example:
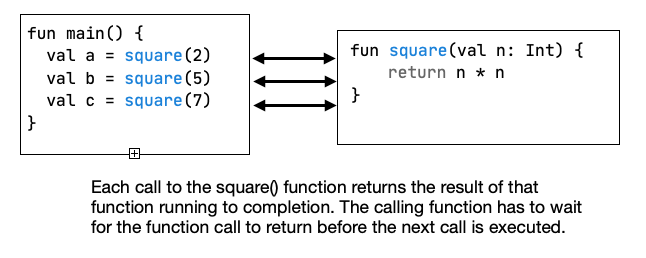
Because they run to completion, a subroutine will block your program from executing any further until the subroutine completes. This may not matter with very quick functions, but in some cases, this can cause your application to appear to “lock up” waiting for a result.
Yes, the OS can preemptively task switch to a different program, but this particular program will remain blocked by default.
This is not an unusual situation: applications often connect with outside resources to download data, query a database, or make a request to a web API, all of which take considerable time and can cause blocking behaviours. Delays like this are unacceptable.
The solution is to design software so that long-running tasks can be run in the background, or asynchronously. Kotlin has support for a number of mechanisms that support this. The most common approach involves manipulating threads.
Threads
A thread is the smallest unit of execution in an application. Typically, an application will have a “main” thread, but we can also create threads to do other work that execute independently of this main thread. Every thread has its own instructions that it executes, and the processor is responsible for allocating time for each thread to run.
Diagrams from https://www.backblaze.com/blog/whats-the-diff-programs-processes-and-threads/
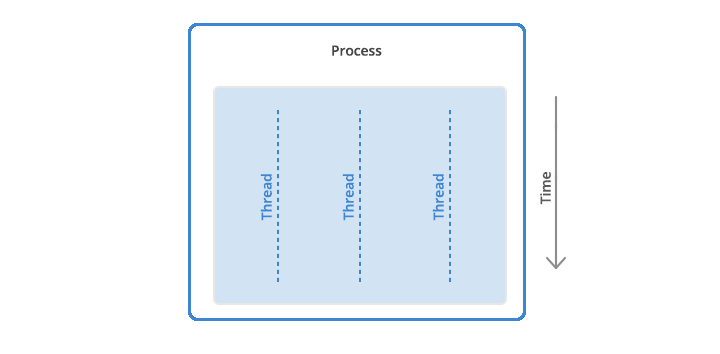
Multi-threading is the idea of splitting up computation across threads – having multiple threads running in-parallel to complete work more quickly. This is also a potential solution to the blocking problem, since one thread can wait for the blocking operation to complete, while the other threads continue processing. Threads like this are also called background threads.
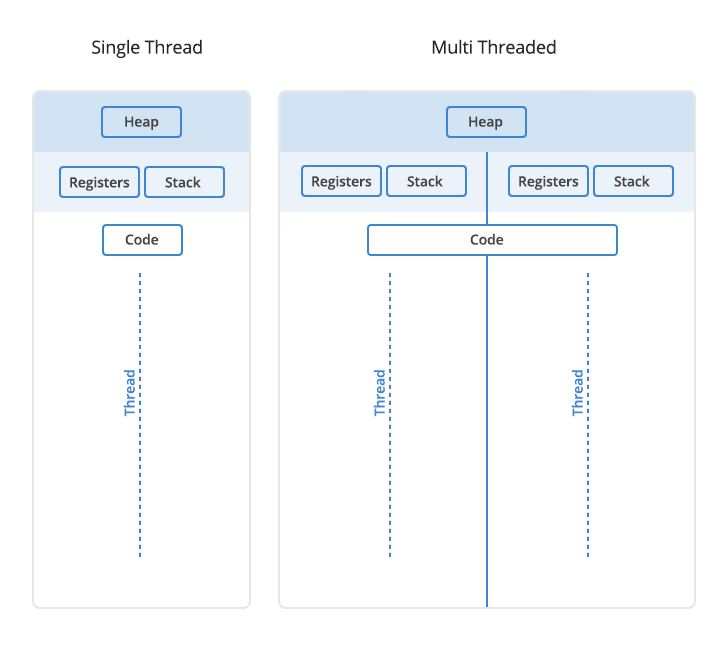
Note from the diagram below that threads have a common heap, but each thread has its own registers and stack. Care must be taken to ensure that threads aren’t modifying the same memory at the same time! I’d recommend taking a course that covers concurrency in greater detail.
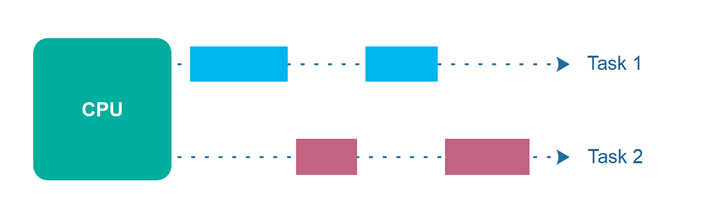
Concurrent vs. Parallel Execution
Concurrent Execution means that an application is making progress on more than one task at a time. This diagram illustrates how a single processor, handling one task at a time, can process them concurrently (i.e. with work being done in-order).
In this example, tasks 1 and 2 are being processed concurrently, and the single CPU is switching between them. Note that there is never a period of overlap where both are executing at the same time, but we have progress being made on both over the same time period.
Diagrams taken from http://tutorials.jenkov.com/java-concurrency/concurrency-vs-parallelism.html
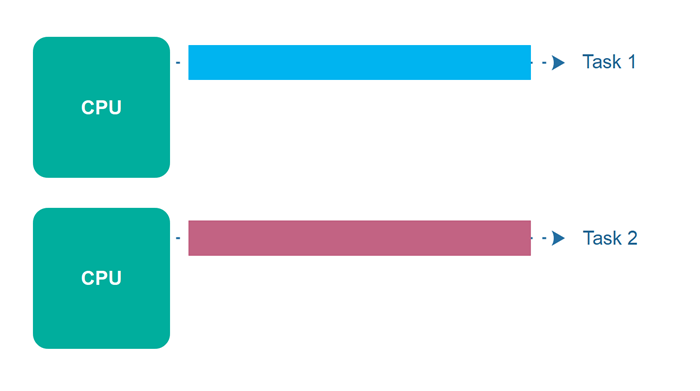
Parallel Execution is where progress can be made on more than one task simultaneously. This is typically done by having multiple threads that can be addressed at the same time by the processor/cores involved.
In this example, both task 1 and task 2 can execute through to completion without interfering with one another, because the system has multiple processors or cores to support parallel execution.
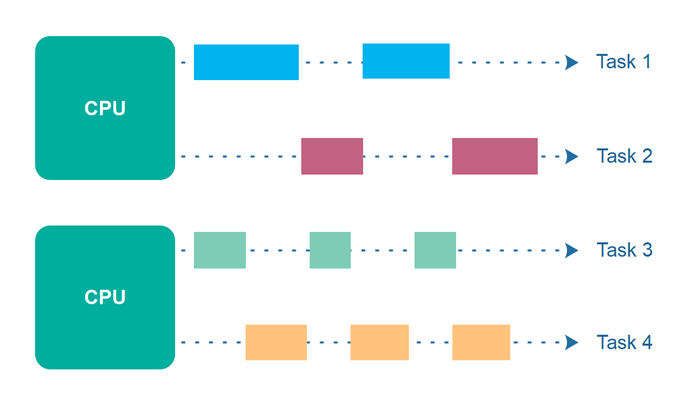
Finally, it is possible to have parallel and concurrent execution happening together. In this example, there are two processors/cores, each responsible for 2 tasks (i.e. CPU 1 handles task 1 and task 2, while CPU 2 handles task 3 and task 4). The CPU can slide up each task and alternate between them concurrently, while the other processor executes tasks in parallel.
So which do we prefer? Both have their uses, depending on the nature of the computation, the processor capabilities and other factors.
Parallel operations happen at the same time, and the operations logically do not interfere with one another. Parallel execution is typically managed by using threads to split computation into different units of execution that the processor can manage them independently. Modern hardware is capable of executing many threads simultaneously, although doing this is very resource intensive, and it can be difficult to manage threads correctly.
Concurrent tasks can be much easier to manage, and make sense for tasks where you need to make progress, but the task isn’t impeded by being interrupted occasionally.
Managing Threads
Kotlin has native support for creating and managing threads. This is done by
- Creating a user thread (distinct from the main thread where your application code typically runs).
- Defining some task for it to perform.
- Starting the thread.
- Cleaning up when it completes.
In this way, threads can be used to provide asynchronous execution, typically running in parallel with the main thread (i.e. running “in the background” of the program).
val t = object : Thread() {
override fun run() {
// define the task here
// this method will run to completion
}
}
t.start() // launch the thread, execution will continue here in the main thread
t.stop() // if we want to halt it from executing
Kotlin also provides a helper method that simplifies the syntax.
fun thread(
start: Boolean = true,
isDaemon: Boolean = false,
contextClassLoader: ClassLoader? = null,
name: String? = null,
priority: Int = -1,
block: () -> Unit
): Thread
// a thread can be instantiated quite simply.
thread(start = true) {
// the thread will end when this block completes
println("${Thread.currentThread()} has run.")
}
There are additional complexities of working with threads if they need to share mutable data: this a significant problem. If you cannot avoid having threads share access to data, then read the Kotlin docs on concurrency first.
Threads are also very resource-intensive to create and manage. It’s temping to spin up multiple threads as we need them, and delete them when we’re done, but that’s just not practical most of the time.
Threads consume roughly 2 MB of memory each. We can easily manage hundreds or thousands of threads, but it’s not unreasonable to picture building a large service that might require 100,000 concurrent operations (or 200 GB or RAM). We can’t reasonably handle that many threads on “regular” hardware.↩
Although threads are the underlying mechanism for many other solutions, they are too low-level to use directly much of the time. Instead, we rely on other abstractions that leverage threads safely behind-the-scenes. We’ll present a few of these next.
Callbacks
Another solution is to use a callback function. Essentially, you provide the long-running function with a reference to a function and let it run on a thread in the background. When it completes, it calls the callback function with any results to process.
The code would look something like this:
fun postItem(item: Item) {
preparePostAsync { token ->
submitPostAsync(token, item) { post ->
processPost(post)
}
}
}
fun preparePostAsync(callback: (Token) -> Unit) {
// make request and return immediately
// arrange callback to be invoked later
}
This is still not an ideal solution.
- Difficulty of nested callbacks. Usually a function that is used as a callback, often ends up needing its own callback. This leads to a series of nested callbacks which lead to incomprehensible code.
- Error handling is complicated. The nesting model makes error handling and propagation of these more complicated.
Promises
Using a promise involves a long-running process, but instead of blocking it returns with a Promise - an object that we can reference immediately but which will be processed at a later time (conceptually like a data structure missing data).
The code would look something like this:
fun postItem(item: Item) {
preparePostAsync()
.thenCompose { token ->
submitPostAsync(token, item)
}
.thenAccept { post ->
processPost(post)
}
}
fun preparePostAsync(): Promise<Token> {
// makes request and returns a promise that is completed later
return promise
}
This approach requires a series of changes in how we program:
- Different programming model. Similar to callbacks, the programming model moves away from a top-down imperative approach to a compositional model with chained calls. Traditional program structures such as loops, exception handling, etc. usually are no longer valid in this model.
- Different APIs. Usually there’s a need to learn a completely new API such as
thenComposeorthenAccept, which can also vary across platforms. - Specific return type. The return type moves away from the actual data that we need and instead returns a new type
Promisewhich has to be introspected. - Error handling can be complicated. The propagation and chaining of errors aren’t always straightforward.
Coroutines
Kotlin’s approach to working with asynchronous code is to use coroutines, which are suspendable computations, i.e. the idea that a function can suspend its execution at some point and resume later on. By default, coroutines are designed to mimic sequential behaviour and avoid by-default concurrency (i.e. it defaults to a simple case, and concurrency has to be explicitly declared).
Many of the explanations and examples were taken directly from the Coroutines documentation. It’s worth looking at the original source for more details.
The flight-data sample was taken from: Andrew Bailey, David Greenhalgh & Josh Skeen. 2021. Kotlin Programming: The Big Nerd Ranch Guide. 2nd Edition. Pearson. ISBN 978-0136891055.
Think of a coroutine as a light-weight thread. Like threads, coroutines can run in parallel, wait for each other and communicate. However, unlike threads, coroutines are not tied to one specific thread, and can be moved around as needed, making them very efficient. Also, compared to threads, coroutines are very cheap. We can easily create thousands of them with very little performance cost.
Coroutines are functions, but they behave differently than regular subroutines. Unlike subroutines which have a single point-of-entry, a coroutine may have multiple points-of-entry and may remember state between calls. This means that we can use coroutines to have cooperating functions, where control is passed back and forth between them. Coroutines can be suspended, or paused, while waiting on results, and the cooperating function can take over execution.
Here’s a quick-and-dirty example that spins up 1000 coroutines quite easily (don’t worry about the syntax yet).
import kotlinx.coroutines.*
fun main() = runBlocking {
repeat(1000) { // launch a lot of coroutines
launch {
delay(100L) // pause each coroutine for 100 ms
print(".") // print something to indicate that it's run
}
}
}
// ....................................................................................................
Kotlin provides the kotlinx.coroutines library with a number of high-level coroutine-enabled primitives. You will need to add the dependency to your build.gradle file, and then import the library.
// build.gradle
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-core:1.6.0'
// code
import kotlinx.coroutines.*
A simple coroutine
Here’s a simple coroutine that demonstrates their use. This example is taken from the Kotlin Docs.
import kotlinx.coroutines.*
fun main() = runBlocking { // this: CoroutineScope
launch { // launch a new coroutine and continue
delay(1000L) // non-blocking delay for 1 second (default time unit is ms)
println("World!") // print after delay
}
println("Hello") // main coroutine continues while a previous one is delayed
}
//output
Hello
World
The section of code within the launch { } scope is delayed for 1 second. The program runs through the last line, prints “Hello” and then prints “World” after a delay.
- runBlocking is a coroutine builder that bridges the non-coroutine world of a regular
fun main()and the code with coroutines inside therunBlocking { ... }curly braces. This is highlighted in an IDE bythis: CoroutineScopehint right after therunBlockingopening curly brace. - launch is also a coroutine builder. It launches a new coroutine concurrently with the rest of the code, which continues to work independently. That’s why
Hellohas been printed first. - delay is a special suspending function. It suspends the coroutine for a specific time. Suspending a coroutine does not block the underlying thread, but allows other coroutines to run and use the underlying thread for their code.
If you remove or forget
runBlockingin this code, you’ll get an error on the launch call, since launch is declared only in the CoroutineScope. “Error: Unresolved reference: launch”.
The use of runBlocking means that the thread that runs it (in this case — the main thread) gets blocked for the duration of the call, until all the coroutines inside runBlocking { ... } complete their execution. You will often see runBlocking used like that at the very top-level of the application and quite rarely inside the real code, as threads are expensive resources and blocking them is inefficient and rarely desirable.
Suspending functions
We can extract the block of code inside launch { ... } into a separate function. When you perform “Extract function” refactoring on this code, you get a new function with the suspend modifier. This is your first suspending function. Suspending functions can be used inside coroutines just like regular functions, but their additional feature is that they can, in turn, use other suspending functions (like delay in this example) to suspend execution of a coroutine.
fun main() = runBlocking { // this: CoroutineScope
launch { doWorld() }
println("Hello")
}
// this is your first suspending function
suspend fun doWorld() {
delay(1000L)
println("World!")
}
// output
Hello
World!
In this case, the main() method runs doWorld() asynchronously in the background, then prints “Hello” before pausing and waiting for the runBlocking context to complete. This is the same behaviour that we had above, but the code is cleaner.
Structured concurrency
Coroutines follow a principle of structured concurrency which means that new coroutines can be only launched in a specific CoroutineScope which delimits the lifetime of the coroutine. The above example shows that runBlocking establishes the corresponding scope and that is why the previous example waits until everything completes before exiting the program.
In a real application, you will be launching a lot of coroutines. Structured concurrency ensures that they are not lost and do not leak. An outer scope cannot complete until all its children coroutines complete.
Coroutine Builders
A coroutine builder is a function that creates a new coroutine. Most coroutine builders also start the coroutine immediately after creating it. The most commonly used coroutine builder is launch, which takes a lambda argument, representing the function that will be executed.
Launch
launch will launch a new coroutine concurrently with the rest of the code, which continues to work independently.
Here’s an example that attempts to fetch data from a remote URL, which takes a few seconds to complete.
import kotlinx.coroutines.*
import java.net.URL
val ENDPOINT = "http://kotlin-book.bignerdranch.com/2e/flight"
fun fetchData(): String = URL(ENDPOINT).readText()
@OptIn(DelicateCoroutinesApi::class)
fun main() {
println("Started")
GlobalScope.launch {
val data = fetchData()
println(data)
}
println("Finished")
}
// output
Started
Finished
However, when we run this program, it completes immediately. This is because after the fetchData() function is called, the program continues executing and completes.
This is due to how the launch builder is designed to behave. Unfortunately running the entire program asynchronously isn’t really what we want. We actually want the fetchData() task to run to completion in the background, and the program halt and wait until that function is complete. To do this, we need a different builder that behaves differently.
runBlocking
runBlocking is also a coroutine builder. The name of runBlocking means that the thread that runs it (in this case — the main thread) gets blocked for the duration of the call, until all the coroutines inside runBlocking { ... } complete their execution.
The runBlocking function is a coroutine builder that blocks its thread until execution of its coroutine is complete. You can use runBlocking to launch coroutines that must all complete before execution continues. As you can see, it reaches the “Finished” statement, but pauses at the end of the scope until the fetchData() completes and returns data.
You can see the difference in behaviour here:
val ENDPOINT = "http://kotlin-book.bignerdranch.com/2e/flight"
fun fetchData(): String = URL(ENDPOINT).readText()
fun main() {
runBlocking {
println("Started")
launch {
val data = fetchData()
println(data)
}
println("Finished")
}
}
// output
Started
Finished
BI0262,ATQ,MXF,Delayed,115
In this case, the launch {} coroutine runs in the background fetching data, while the program continues running. After println("Finished") executes, and it’s at the end of the runBlocking scope, it halts and waits for the launch coroutine to complete before exiting the program.
coroutineScope
In addition to the coroutine scope provided by different builders, it is possible to declare your own scope using the coroutineScope builder. It creates a coroutine scope and does not complete until all launched children complete.
runBlocking and coroutineScope builders may look similar because they both wait for their body and all its children to complete. The main difference is that the runBlocking method blocks the current thread for waiting, while coroutineScope just suspends, releasing the underlying thread for other usages.
You can use coroutineScope from any suspending function. For example, you can move the concurrent printing of Hello and World into a suspend fun doWorld() function:
fun main() = runBlocking {
doWorld()
}
suspend fun doWorld() = coroutineScope { // this: CoroutineScope
launch {
delay(1000L)
println("World!")
}
println("Hello")
}
// output
Hello
World!
A coroutineScope builder can be used inside any suspending function to perform multiple concurrent operations. Let’s launch two concurrent coroutines inside a doWorld suspending function:
// Sequentially executes doWorld followed by "Done"
fun main() = runBlocking {
doWorld()
println("Done")
}
// Concurrently executes both sections
suspend fun doWorld() = coroutineScope { // this: CoroutineScope
launch {
delay(2000L)
println("World 2")
}
launch {
delay(1000L)
println("World 1")
}
println("Hello")
}
// output
Hello
World 1
World 2
Done
Managing a coroutine
A launch coroutine builder returns a Job object that is a handle to the launched coroutine and can be used to explicitly wait for its completion. For example, you can wait for completion of the child coroutine and then print “Done” string:
val job = launch { // launch a new coroutine and keep a reference to its Job
delay(1000L)
println("World!")
}
println("Hello")
job.join() // wait until child coroutine completes
println("Done")
In a long-running application you might need fine-grained control on your background coroutines. For example, a user might have closed the page that launched a coroutine and now its result is no longer needed and its operation can be cancelled. The launch function returns a Job that can be used to cancel the running coroutine:
val job = launch {
repeat(1000) { i ->
println("job: I'm sleeping $i ...")
delay(500L)
}
}
delay(1300L) // delay a bit
println("main: I'm tired of waiting!")
job.cancel() // cancels the job
job.join() // waits for job's completion
println("main: Now I can quit.")
// output
job: I'm sleeping 0 ...
job: I'm sleeping 1 ...
job: I'm sleeping 2 ...
main: I'm tired of waiting!
main: Now I can quit.
As soon as main invokes job.cancel, we don’t see any output from the other coroutine because it was cancelled.
Composing suspending functions
Sequential (default)
Assume that we have two suspending functions defined elsewhere that do something useful like some kind of remote service call or computation. What do we do if we need them to be invoked sequentially — first doSomethingUsefulOne and then doSomethingUsefulTwo, and compute the sum of their results? We use a normal sequential invocation, because the code in the coroutine, just like in the regular code, is sequential by default.
suspend fun doSomethingUsefulOne(): Int {
delay(1000L) // pretend we are doing something useful here
return 13
}
suspend fun doSomethingUsefulTwo(): Int {
delay(1000L) // pretend we are doing something useful here, too
return 29
}
val time = measureTimeMillis {
val one = doSomethingUsefulOne()
val two = doSomethingUsefulTwo()
println("The answer is ${one + two}")
}
println("Completed in $time ms")
// output
The answer is 42
Completed in 2017 ms
Concurrent (async)
What if there are no dependencies between invocations of doSomethingUsefulOne and doSomethingUsefulTwo and we want to get the answer faster, by doing both concurrently? Use async, another builder.
Conceptually, async is just like launch. It starts a separate coroutine which is a light-weight thread that works concurrently with all the other coroutines. The difference is that launch returns a Joband does not carry any resulting value, while async returns a Deferred — a light-weight non-blocking future that represents a promise to provide a result later. You can use .await() on a deferred value to get its eventual result, but Deferred is also a Job, so you can cancel it if needed.
val time = measureTimeMillis {
val one = async { doSomethingUsefulOne() }
val two = async { doSomethingUsefulTwo() }
println("The answer is ${one.await() + two.await()}")
}
println("Completed in $time ms")
// output
The answer is 42
Completed in 1017 ms
For more examples, the Kotlin Docs Coroutine Tutorial is highly recommended!