Databases
Persisting data directly to files can be convenient, but it doesn’t scale well to large amounts of data. It’s also cumbersome to work with. A more robust solution is to store data in a database: a system designed for organizing and managing large amounts of data efficiently.
Databases range in size and complexity from simple file-based databases that run on your local computer, to large scalable databases that run on a server cluster. They are optimized for fetching text and numeric data, and performing operations like sorting, grouping and filtering on this data.
Databases also have the advantage of scaling really well in multiple dimensions. They’re optimized for efficient storage and retrieval of large amounts of data, but also for concurrent access by hundreds or thousands of users.
This is a huge and complex topic; we’re not even scratching the surface. I’d strongly encourage you to take a more comprehensive database course e.g. CS 348.
Types of Databases
Databases structure data as logical records. A record is a collection of related data, organized into fields. For example, a record might represent a customer, with fields for name, address, and phone number.
// name, address, phone
John Doe, 123 Main St, 555-1234
Jane Smith, 456 Elm St, 555-5678
Bob Johnson, 789 Oak St, 555-9012
Part of the challenge of working with databases is designing the structure to store your data. The data model defines the tables, fields, and relationships between records. A data model should support
- efficient storage of data, with minimal duplication,
- efficient retrieval of data, and
- easy modification of data.
Ideally, we also want to support translation of records between different representation formats (this will be a theme that we revisit later).
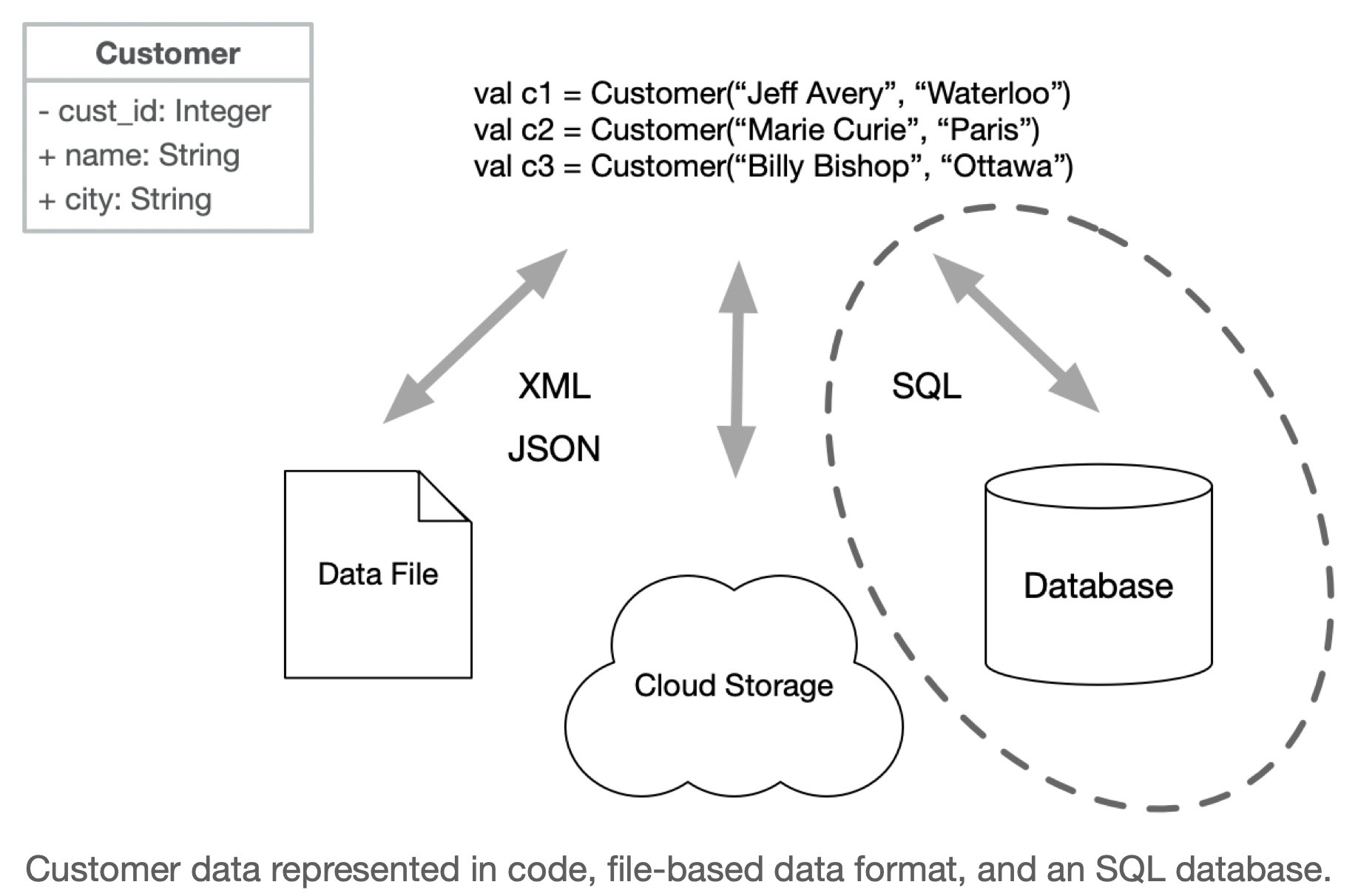
There are different types of databases, which differ in how they structure and organize data. The largest division is between SQL (relational) and NoSQL (non-relational) databases.
Relational (SQL) databases are based on the relational model, which organizes data into tables with rows and columns. Records are split across tables to avoid data duplication, and fetching records often requires queries that span multiple tables. Examples of relational databases include Oracle, MySQL, PostgreSQL, and SQLite.
No-SQL is a very broad category, which can either mean “Not Only SQL” or “No SQL”. These databases are designed to handle data that doesn’t fit well into the traditional relational model. Types of No-SQL databases include:
- Document databases (e.g. MongoDB)
- Key-value stores (e.g. Redis)
- Graph databases (e.g. Neo4j)
- Time-series databases (e.g. InfluxDB)

We’ll discuss two types of databases in this course: relational/SQL databases and document/NoSQL databases.
For the sake of simplicity in this section, we’ll focus on databases in isolation, rather than as part of a larger system. This is a little simplistic, since databases are usually managed as part of a larger system that includes a web server, application server, and other components.
To avoid the complexities of maintaining your own server infrastructure, you should probably use a hosted, cloud database for your project i.e. one that is hosted and managed by a third-party. We’ll discuss cloud computing in the next section.
Relational Databases
A relational database (sometimes referred to as a SQL database) is a database design that structures records as entries in one or more tables.
- A
tableis a two-dimensional grid, with rows and columns. Each row represents a records, and each row contains one or more columns which represent fields. Tables are meant to hold related data e.g. one table might hold Customer data, another might hold Order data. - A
rowis a single record, with each columns as a field in that record. For example, our customer record might have fields for name, address, and phone number. - A
columnis one of the fields in the row. e.g. name or address.
A simple relational table to store customer information might look something like this:
| Name | Address | City | Phone Number |
|---|---|---|---|
| John Doe | 123 Main St | Waterloo | 555-1234 |
| Jane Smith | 456 Elm St | Vancouver | 555-5678 |
| Bob Johnson | 123 Main St | Bancroft | 555-9012 |
Primary Keys
This structure isn’t very robust. What if we have two people with the same name? This isn’t unusual in a large city. For example, we might have two Jane Smiths, living at different addresses.
| Name | Address | City | Phone Number |
|---|---|---|---|
| John Doe | 123 Main St | Waterloo | 555-1234 |
| Jane Smith | 456 Elm St | Vancouver | 555-5678 |
| Bob Johnson | 123 Main St | Bancroft | 555-9012 |
| Jane Smith | 555 Pine Cres | Vancouver | 555-5309 |
When querying this data, we need some way to differentiate between the two Jane Smiths. We do this by adding a unique identifier to each record, called a primary key. This is a unique identifier for each record in the table - typically generated by the database itself when the record is created. We would consider this an artificial identifier, since we’re generating a unique key (as opposed to a natural identifier, like their name). Generating artificial identifiers is standard practice when working with large volumes of data.
A better table structure that includes a primary key would look like this:
| Cust_ID | Name | Address | City | Phone Number |
|---|---|---|---|---|
| 1001 | John Doe | 123 Main St | Waterloo | 555-1234 |
| 1002 | Jane Smith | 456 Elm St | Vancouver | 555-5678 |
| 1003 | Bob Johnson | 123 Main St | Bancroft | 555-1234 |
| 1004 | Jane Smith | 555 Pine Cres | Vancouver | 555-5309 |
Now we know that “Cust_ID=1002” is the Jane Smith on Elm Street, and “Cust_ID=1004” is the Jane Smith on Pine Crescent. There is no confusion!
Why are the keys so small?? Why not use a UUID or some other mechanism to generate a unique key? Smaller keys are faster to search and sort, and more space efficient. In a table of 4 records, it makes little difference, but you might eventually need to store millions of records.
Foreign Keys
To make our data storage more efficient, we can split our data across multiple tables. This is called normalization. For example, we might replace our single Customer table with a Customer table, an Address table and a Phone table.
Why would you want to do this?
- Your customer might have multiple phone numbers e.g., home, work, cell. A single table structure above doesn’t handle this i.e., you would need to add
PhoneandPhone2columns, which would then fail if a customer had a third phone number! - You might have multiple customers at the same address e.g, a family. Our earlier table structure doesn’t handle this very well either.
Here’s what a normalized schema might look like.
A customer table holds name only, and links to other tables.
| Cust_ID | Name | Address_ID | Phone_ID |
|---|---|---|---|
| 1 | John Doe | 1 | 1 |
| 2 | Jane Smith | 2 | 2 |
| 3 | Bob Johnson | 1 | 1 |
| 4 | Jane Smith | 3 | 3 |
Address is split out:
| Address_ID | Address | City |
|---|---|---|
| 1 | 123 Main St | Waterloo |
| 2 | 456 Elm St | Vancouver |
| 3 | 555 Pine Cres | Vancouver |
Phone number is split out:
| Phone_ID | Phone Number |
|---|---|
| 1 | 555-1234 |
| 2 | 555-5678 |
| 3 | 555-5309 |
Notice that in the Customer table, we’ve replaced address with Address_ID, the primary key on our Address table. This is called a foreign key - a reference in one table (Customer) to a primary key in another table (Address).
To reconstruct John Doe’s complete record, we need to pull the data from the Customer, Address and Phone tables.
- We look up John Doe (
Custom_ID=1) in theCustomertable. - Using the
Address_ID=1, we look up the record in theAddresstable. - Using the
Phone_ID=1, we look up the record in thePhonetable. - We use this data to reconstruct the complete record as:
John Doe, 123 Main St Waterloo, 555-1234.
We have duplicate keys i.e. “1” is the value of Cust_ID in one table, and Address_ID in another. This is a problem? No not at all! We only ever refer to the key value in the context of a table. i.e. PhoneID=1 or Address_ID=1. You cannot refer to a key’s value without also referencing the column where it is being used.
Data Models
Here’s our earlier example shown as a class, a set of records in a CSV file and as a set of relational database tables. Note that we’ve added a cust_id field, as a unique identifier for each record in the Custom table.
We refer to the cust_id field as a primary key or a unique identifier for each record in that table. We’ll return to this idea in the next section, when we start discussing SQL.
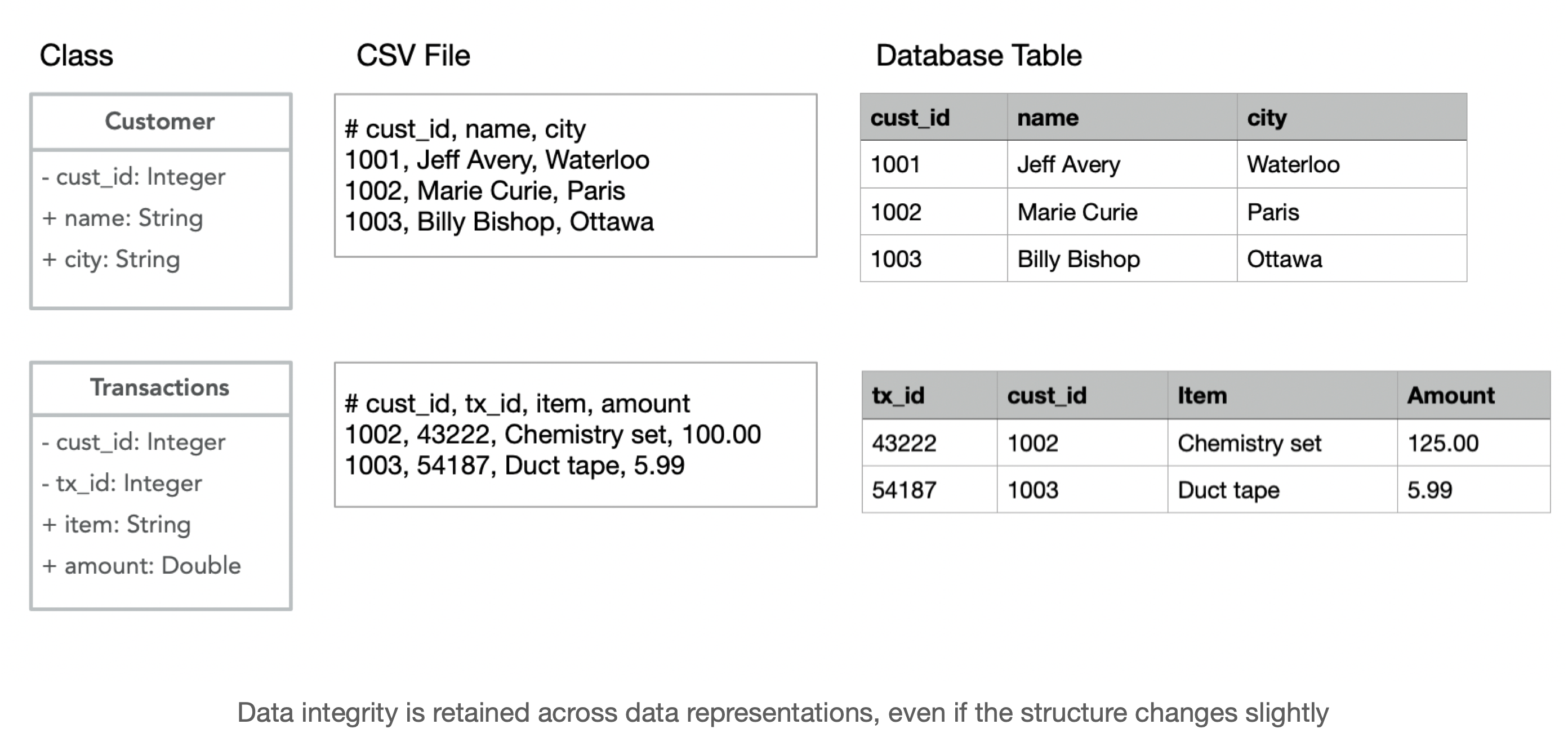
Why is the relational approach valuable? Relational databases can perform efficient operations on sets of records. For example:
- Return a list of all purchases greater than $100.
- Return a list of customers from “Paris”.
- Delete customers from “Ottawa”.
Our example is pretty trivial, but imagine useful queries like:
- “Find all transactions between 2:00 and 2:30”, or
- “Find out which salesperson sold the greatest amount during last Saturday’s sale”.
What is SQL?
SQL (“Ess-que-ell”) is a Domain-Specific Language (DSL) for describing your queries against a relational database. Using SQL, you write statements describing the operation to perform and which tables to use, and the database performs the operations for you.
SQL is a standard, so SQL commands work across different databases. SQL was adopted as a standard by ANSI in 1986 as SQL-86, and by ISO in 1987.
Using SQL, you can:
- Create new records
- Retrieve sets of existing records
- Update the fields in one or more records
- Delete one or more records
These are considered the basic functions for working with persistent storage. Yes, we use the acronym CRUD. You’ll occasionally trip over the term “CRUD applications” which just means an application whose primary purpose is to interact with an underlying database. An example would be something like a simple app for tracking a list of customers or sales data.
SQL has a specific syntax for managing sets of records:
<operation> FROM [table] [WHERE [condition]]
operations: SELECT, UPDATE, INSERT, DELETE, ...
conditions: WHERE [col] <operator> <value>
For example:
/* SELECT returns data from a table, or a set of tables.
* an asterix (*) means "all"
*/
SELECT * FROM customers
SELECT * FROM Customers WHERE city = "Ottawa"
SELECT name FROM Customers WHERE custid = 1001
/* UPDATE modifies one or more column values based on some criteria.*/
UPDATE Customer SET city = "Kitchener" WHERE cust_id = 1001
UPDATE Customer SET city = "Kitchener" // uh oh, what is wrong with this?
/* INSERT adds new records to your database. */
INSERT INTO Customer(cust_id, name, city)
VALUES ("1005", "Meredith Avery", "Kitchener")
INSERT INTO Customer(cust_id, name, city)
VALUES ("1005", "Brian Avery", "Kitchener") // uh oh, what have I done?
It’s common to have a record spread across multiple tables. A join describes how to relate data across tables.
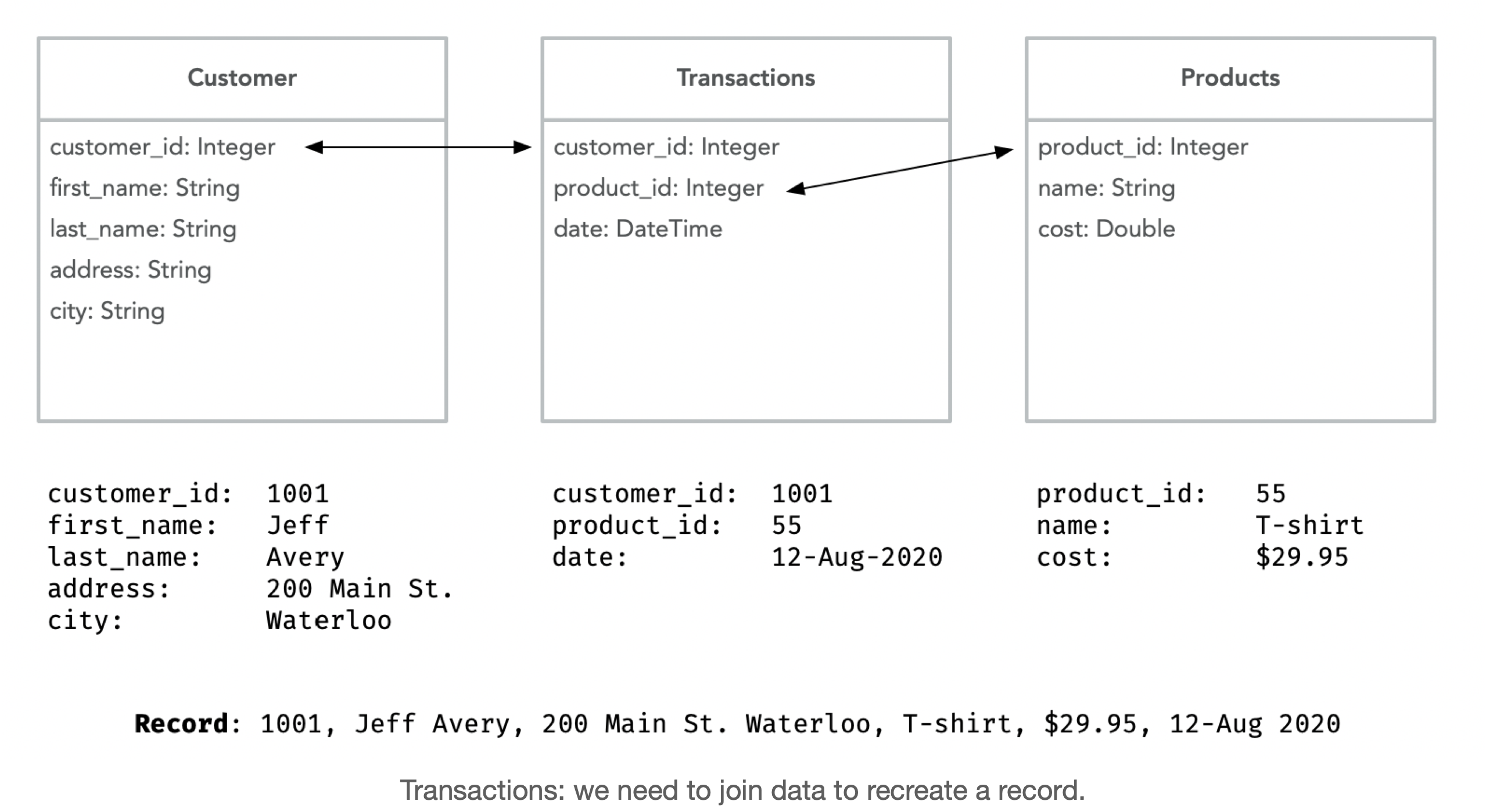
SELECT c.customer_id, c.first_name + “ “ + c.last_name, t.date, p.name, p.cost
FROM Customer c, Transactions t, Products p
WHERE c.customer_id = t.customer_id
AND t.product_id = p.product_id
Returns data that spans multiple tables:
$ 1001, Jeff Avery, 12-Aug-2020, T-shirt, 29.95
Using JDBC
Some online databases have their own libraries that you can use for connecting (see examples above). It’s also common to use a standard library called JDBC (Java Database Connectivity) to connect to a database. JDBC is a Java API that provides a standard way to connect to a database, issue SQL queries, and retrieve results.
To create a database project in IntelliJ using JDBC:
-
Create a Gradle/Kotlin project.
-
Modify the
build.gradleto include a dependency on the JDBC driver for your database.
// choose the driver for your particular database
implementation("org.xerial:sqlite-jdbc:3.42.0.0")
- Use the Java SQL package classes to connect and fetch data.
import java.sql.Connection
import java.sql.DriverManager
import java.sql.SQLException
Different databases require different JDBC drivers. You can typically find JDBC drivers (and the appropriate implementation statement) on maven.
Connecting with JDBC
To connect to a database, we use the Connection class with a connection string representing the details on how to connect.
Here’s how we connect to the SQLite driver.
// sqlite database (file-based)
val url = "jdbc:sqlite:chinook.db"
conn = DriverManager.getConnection(url)
The connection string contains these components:
- jdbc: the type of connection, this is a fixed string
- sqlite: the type of database
- chinook.db: the filename since this is a file-based database
This example uses a sample database from the official SQLite tutorial.
fun connect(): Connection? {
var connection: Connection? = null
try {
val url = "jdbc:sqlite:chinook.db"
connection = DriverManager.getConnection(url)
println("Connection is valid.")
} catch (e: SQLException) {
println(e.message)
}
return connection
}
We are using a samples database called
chinook.dbwhich is available for many different databases. You can download scripts to create it from here.
Querying Data Interacting with the database through an active connection involves preparing a query, executing it, and then iterating over the results.
!!!warning Make sure to close your results, query and connection when you are done with them! !!!
data class Artist(val id:Int, val name: String)
fun Connection.getArtists(): List<Artist> {
val artists = mutableListOf<Artist>()
val query = prepareStatement("SELECT * FROM artists")
val result = query.executeQuery()
while(result.next()) {
artists.add(
Artist(
result.getInt("ArtistID"),
result.getString("Name")
)
)
}
fun main() {
val connection = connect()
val artists = connection?.getArtists()
println("${artists?.size} records retrieved")
connection?.close()
}
Examples
SQLite (Local)
Relational databases are often large and complex systems. However, the relational approach can also be scaled-down.
SQLite (pronounced ESS-QUE-ELL-ITE) is a small-scale relational DBMS that supports SQL. It is small enough for local, standalone use.
SQLite is a C-language library that implements a small, fast, self-contained, high-reliability, full-featured, SQL database engine. SQLite is the most used database engine in the world. SQLite is built into all mobile phones and most computers… https://www.sqlite.org/index.html
You can install the SQLite database under Mac, Windows or Linux.
- Visit the SQLite Download Page.
- Download the binary for your platform.
- To test it, launch it from a shell.
$ sqlite3
SQLite version 3.28.0 2019-04-15 14:49:49
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
sqlite> .exit
We will create a database from the command line. Optionally, you can install SQLite Studio, a GUI for managing databases.
You can download the SQLite Sample Database and confirm that SQLite is working. We can open and read from this database using the command-line tools:
$ sqlite3
SQLite version 3.32.3 2020-06-18 14:16:19
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
sqlite> .help
.auth ON|OFF Show authorizer callbacks
.backup ?DB? FILE Backup DB (default "main") to FILE
.bail on|off Stop after hitting an error. Default OFF
.binary on|off Turn binary output on or off. Default OFF
.cd DIRECTORY Change the working directory to DIRECTORY
.changes on|off Show number of rows changed by SQL
.check GLOB Fail if output since .testcase does not match
.clone NEWDB Clone data into NEWDB from the existing database
.databases List names and files of attached databases
.dbconfig ?op? ?val? List or change sqlite3_db_config() options
.dbinfo ?DB? Show status information about the database
Commands
These commands are meta-commands that act on the database itself, and not the data that it contains (i.e. these are different from SQL and specific to SQLite). Some particularly useful commands:
{.compact}
| Command | Purpose |
|---|---|
.open filename | Open database filename. |
| .database | Show all connected databases. |
.log filename | Write console to log filename. |
.read filename | Read input from filename. |
| .tables | Show a list of tables in the open database. |
.schema tablename | SQL to create a particular tablename. |
| .fullschema | SQL to create the entire database structure. |
| .quit | Quit and close connections. |
We often use these meta-commands to change settings, and find information that we’ll need to structure queries e.g. table names.
$ sqlite3
SQLite version 3.28.0 2019-04-15 14:49:49
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
sqlite> .open chinook.db // name of the file
sqlite> .mode column // lines up data in columns
sqlite> .headers on // shows column names at the top
// determine which tables to query
sqlite> .tables
albums employees invoices playlists
artists genres media_types tracks
customers invoice_items playlist_track
Queries Once we’ve identified what we want to do, we can just execute our queries. Examples of selecting from a single table at a time:
sqlite> SELECT * FROM albums WHERE albumid < 4;
AlbumId Title ArtistId
---------- ------------------------- ----------
1 For Those About To Rock 1
2 Restless and Wild 2
3 Let There Be Rock 1
sqlite> SELECT * FROM artists WHERE ArtistId = 1;
ArtistId Name
---------- ----------
1 AC/DC
We can also JOIN across two tables (based on a primary key, ArtistId). You often will have multiple WHERE clauses to join between multiple tables.
sqlite> SELECT albums.AlbumId, artists.Name, albums.Title
FROM albums, artists
WHERE albums.ArtistId = artists.ArtistId
AND albums.AlbumId < 4;
AlbumId Name Title
---------- ---------- ------------------------
1 AC/DC For Those About To Rock
2 Accept Restless and Wild
3 AC/DC Let There Be Rock
Supabase (Remote)
SQLite is a local, lightweight solution, suitable for standalone applications. What if you want a SQL database that can be shared? There are many solutions for hosting a database in the cloud.
Supabase is a new open-source project that provides a cloud-hosted relational database. It’s built on top of PostgreSQL, a powerful open-source SQL database. They also have a free tier, which is great for learning and small projects.
For details on using Supabase in your Android project, see the Kotlin Client Library. For other platforms, the community has produced a Kotlin Multiplatform Client for Supabase which we’ve used successfully in this course.
Document Databases
A document database typically stores data in a format called a document. A document is a JSON-like object that contains key-value pairs. In the case of MonboDB, these documents are are also stored in collections.
Comparing a document database to a relational database, you can think of a collection as comparable to a table, and a document as a record in a table, containing fields. Here’s an example of a customer document in a document database, with fields for name, address, and phone number:
{
"name": "John Doe",
"address": "123 Main St",
"city": "Waterloo",
"phone": "555-1234"
}
Unlike a relational database, a document database doesn’t require a fixed schema. This means that each document in a collection can have different fields. This flexibility can be useful when you have data that doesn’t fit neatly into a table. However, it can also make it more difficult to query the data.
The other major difference between document databases and relational databases is that document databases don’t support joins. Instead, you typically denormalize the data by embedding related data within a document. This can make it easier to retrieve the data, but it can also make it more difficult to update the data. Duplication of data is a common trade-off in document databases.
Advantages
- You do not need to join across tables to return a record, since the document is a self-contained record.
- You have the flexibility to structure your document as you see fit! It’s incredibly flexible.
- It can be high performance since data does not need to be heavily processed to be stored.
Disadvantages
- Since you can’t join across tables, you need to denormalize your data. This can lead to data duplication.
- Since you can’t count on a fixed structure, it is difficult to perform operations across multiple documents e.g., sorting records is challenging, and sometimes not possible.
Examples
MongoDB
MongoDB is a very popular document database. It stores data in a format called BSON (Binary JSON), which is a binary-encoded serialization of JSON-like documents. MongoDB is designed to be scalable and flexible, and it’s extremely well supported and documented.
It also includes a free-tier cloud service called MongoDB Atlas that you can use to host your databases.
For details on connecting to MongoDB, see the Kotlin Driver Quick Start. Unlike SQL, MongoDB uses a platform specific query language called MongoDB Query Language.
Choosing a Database
Your choice of database depends on a number of factors:
Do you want to run it locally (and keep it exclusive to your application) or run it in the cloud (where you can share access)? Most of the time, we want the benefits of sharing our data - that’s often why we have a database! However, it’s not uncommon for applications to ship with local databases e.g., SQLite for local configuration information, instead of saving data in a text file.
Also, the choice of SQL or NoSQL is a complex decision (well beyond the scope of this course). SQL databases are stable and extremely well supported, but do not scale well to large distributed applications. With the move to cloud-hosting services, NoSQL has become much more popular in recent years. It may be that you choose NoSQL simply because it’s so well supported by cloud vendors and suits a distributed environment much better.
We suggest working through the technical decisions in-order:
- Pick SQL or No-SQL.
- Pick local or hosted (cloud).
- Pick desktop or Android.
| SQL Databases | Local | Cloud |
|---|---|---|
| Android | SQLite | Supabase |
| Desktop | SQLite | Supabase |
| NoSQL Databases | Local | Cloud |
|---|---|---|
| Android | (ScyllaDB, Cassandra) | Firebase |
| Desktop | (ScyllaDB, Cassandra) | MongoDB |
Databases in italics are those that I’ve heard-of, and which seem well-suited to this combination, but which I’ve never actually used. Caveat emptor.