Data formats
Review how to represent, store and manipulate user data.
Most software operates on data. This might be a primary function of your application (e.g. image editor) or a secondary function (e.g. user preferences). As a software developer, you need to give considerable thought to how you will handle user data.
Some examples of data that you might care about:
- The data that the user has captured and wishes to save e.g. an image that they have created in an image-editor, or the text from a note.
- The position and size of the application window, window size, or other settings that you might want to save and restore when the application is relaunched.
- User preferences that they might set in your application e.g. preferred font or font size.
- The public key to connect to a remote machine.
- The software license key for your application.
Operations you may need to do:
- Store data in a file so that you can load and restore it later.
- Transfer the data to another process that can use it, or to a completely different system e.g. over the internet.
- Filter it to a subset of your original data. Sort it. Modify it.
Let’s start by reviewing something we already know: data types.
Data Types
A type is a way of categorizing our data so that the computer knows how we intend to use it. There are many different kinds of types that you already know how to work with:
-
Primitive Types: these are intrinsically understood by a compiler, and will include boolean, and numeric data types. e.g. boolean, integer, float, double.
-
Strings: Any text representation which can include characters (char) or longer collections of characters (string). Strings are complicated to store and manipulate because there are a large number of potential values for each character, and the strings themselves are variable length e.g. they can span a few characters to many thousands of words in a single string!
-
Compound data types: A combination of primitive types. e.g. an Array of Integers.
-
Pointers: A data type whose value points to a location in memory. The underlying data may resemble a long Integer, but they are treated as a separate type to allow for specific behaviours to help protect our programs e.g. to prevent invalid memory access or invalid operations.
-
Abstract data type: We treat ADTs as different because they describe a structure, and do not actually hold any concrete data. We have a template for an ADT (e.g. class) and concrete realizations (e.g. objects). These can be singular, or stored as Compound types as well e.g. an Array of Objects.
You’re accustomed to working with most of these types – we declare variables in a programming language using the types for that language. For example, in Kotlin, we can assign the value 4 to different variables, each representing a different type. Note that we’ve had to make some adjustments to how we represent the value so that they match the expected type, and avoid compiler errors:
val a:Int = 4
val b:Double = 4.0
val c:String = "4"
By using different types, we’ve made it clear to the compiler that a and b do not represent the same value.
a==b
error: operator '==' cannot be applied to 'Int' and 'Double'
Types have properties and behaviours that are specific to that type. For example, we can determine the length of c, a String, but not the length of a, an Int. Similarly, we can perform mathematical operations on some types but not others.
c.length
res13: kotlin.Int = 1
a.length
error: unresolved reference: length
a.length
^
b/4
res15: kotlin.Double = 1.0
c/4
error: unresolved reference. None of the following candidates is applicable because of receiver type mismatch:
public inline operator fun BigDecimal.div(other: BigDecimal): BigDecimal defined in kotlin
public inline operator fun BigInteger.div(other: BigInteger): BigInteger defined in kotlin
c/4
^
In order for our programs to work with data, it needs to be stored in one of these types: either a series of primitives or strings, or a collection of these types, or an instance of an ADT (i.e. an Object).
Keep in mind that this is not the actual data representation, but the abstraction that we are using to describe our data. In memory, a string might be stored as a continuous number of bytes, or scattered through memory in chunks - for this discussion, that doesn’t matter. We’re relying on the programming language to hide away the underlying details.
Data can be simple, consisting of a single field (e.g. the user’s name), or complex, consisting of a number of related fields (e.g. a customer with a name, address, job title). Typically, we group related data into classes, and class instances are used to represent specific instances of that class.
data class Customer(id:Int, name:String, city:String)
val new_client = Customer(1001, "Jane Bond", "Waterloo")
Data items can be singular (e.g. one particular customer), or part of a collection (e.g. all of my customers). A singular example would be a custom record.
val new_client1 = Customer(1001, "Jane Bond", "Waterloo")
val new_client2 = Customer(1002, "Bruce Willis", "Kitchener")
A bank might also keep track of transactions that a customer makes, where each transaction represents the deposit or withdrawal, the date when it occurred, the amount and so on. (This date format is ISO 8601, a standard date/time representation.)
To represent this in memory, we might have a transaction data class, with individual transactions being stored in a collection.
data class Tx(id:Int, date:String, amount:Double, currency: String)
val transactions = mutableList()
transactions.add(Tx(1001, "2020-06-06T14:35:44", "78.22", "CDN"))
transactions.add(Tx(1001, "2020-06-06T14:38:18", "12.10", "USD"))
transactions.add(Tx(1002, "2020-06-06T14:42:51", "44.50", "CDN"))
These structures represent how we are storing this data in this particular case. Note that there may be multiple ways of representing the same data, we’ve just chosen one that makes sense to use.
Data Models
A data model is a abstraction of how our data is represented and how data elements relate to one another. We will often have a canonical data model, which we might then use as the basis for different representations of that data.
There are different forms of data models, including:
- Database model: describes how to structure data in a database (flat, hierarchical, relational).
- Data structure diagrams (DSD): describes data as entities (boxes) and their relationships (arrows connecting them).
- Entity-Relationship Model: Similar to DSDs, but with some notational differences. Don’t scale out very well.
Data structure diagrams aren’t commonly used to diagram a complete system, but can be used to show how entities relate to one another. They can range in complexity from very large and formals diagrams, to quick illustrative sketches that just show the relationships between different entities.
Here’s a data structure diagram, showing different entities. These would likely be converted to multiple classes, each one responsible for their own data.
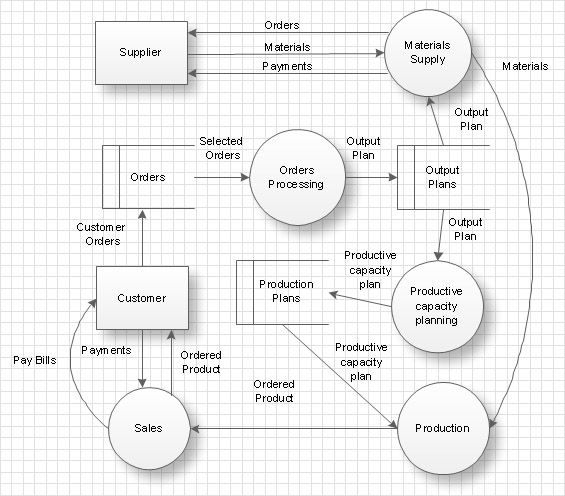
We also use these terms when referring to complex data structures:
- field: a particular piece of data, corresponding to variables in a program.
- record: a collection of fields that together comprise a single instance of a class or object.
Data Representation
One of the challenges is determining how to store our data for different purposes.
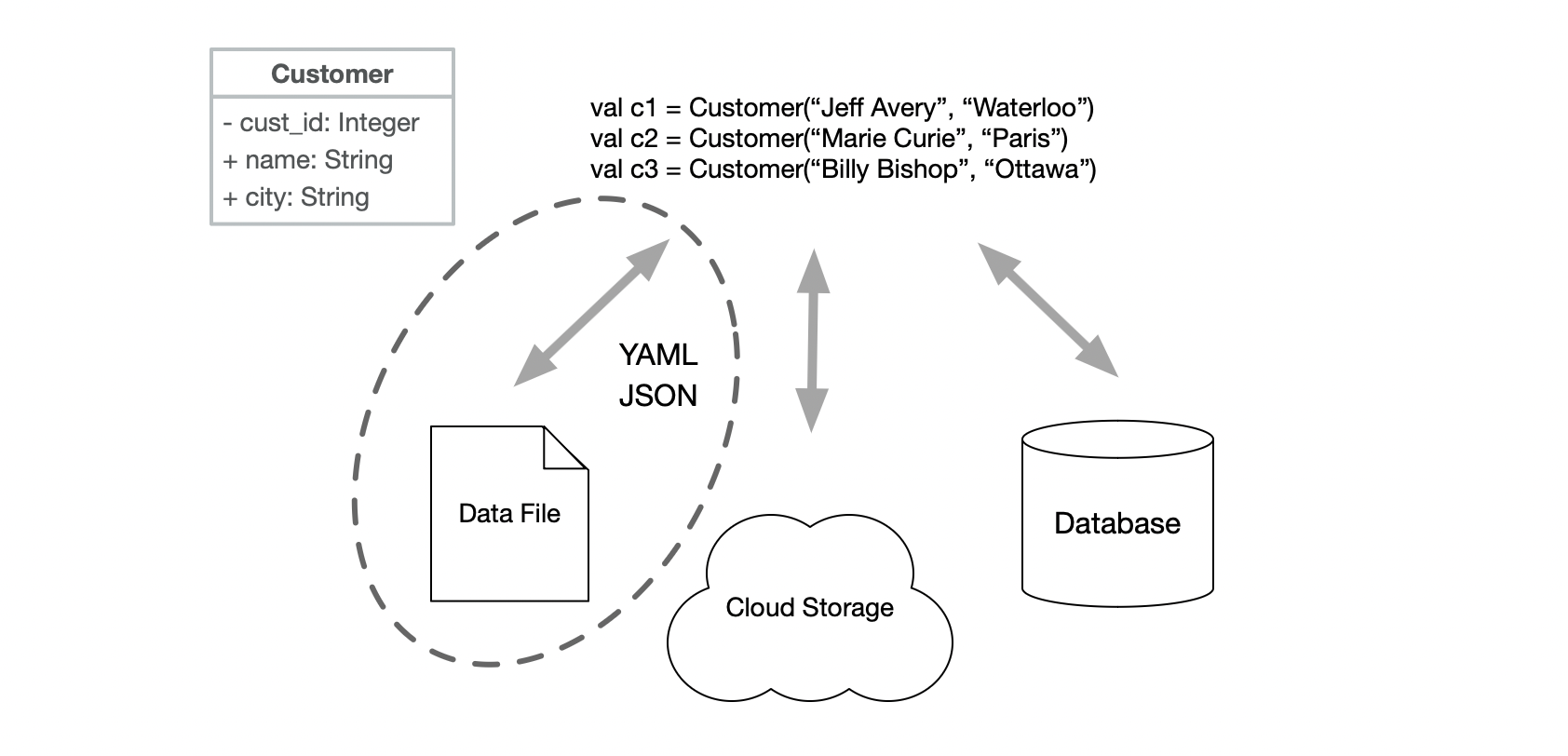
Let’s consider our customer data. We can represent this abstractly as a Customer class. In code, we can have instances of Customers. How do we store that data, or transfer it to a different system?
The “easy” answer would be to share the objects directly, but that’s often not realistic. The target system would need to be able to work with that object format directly, and it’s likely not a very robust (or safe) way of transmitting your data.
Often we need to convert our data into different representations of the same data model.
- We need to ensure that we don’t lose any data
- We need to maintain the relationships between data elements.
- We need to be able to “convert back” as needed.
In the diagram below, you can see this in action. We might want to save our customer data in a database, or into a data file for backup (or transmission to a different system).
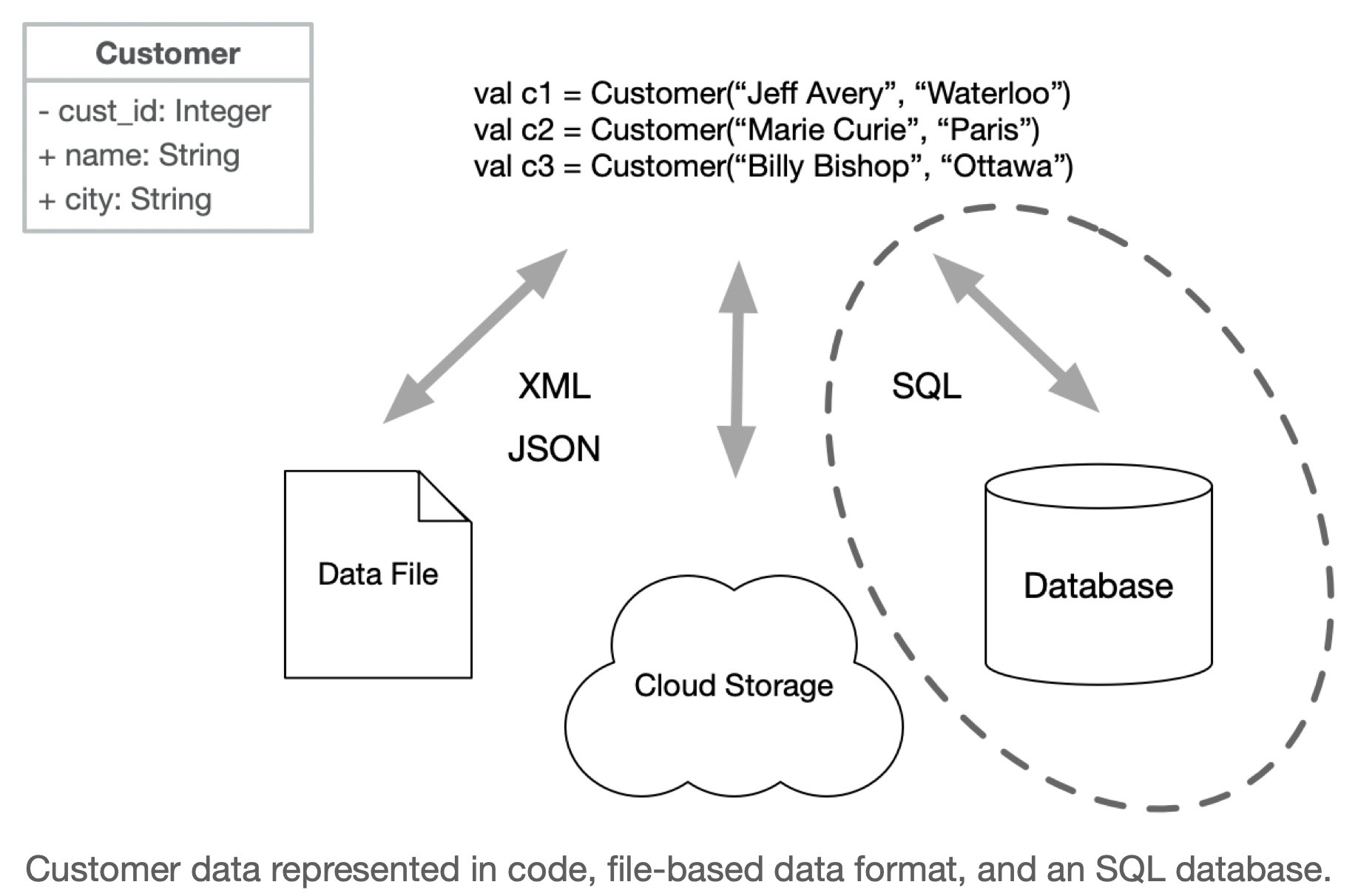
Part of the challenge in working with data is determining what you need to do with it, and what data representation will be appropriate for different situations. As we’ll see, it’s common to need to convert and manage data across these different representations.
Character Encoding
Writing text into a file isn’t as simple as it sounds. Like other data, characters in memory are stored as binary i.e. numeric values in a range. To display them, we need some agreement on what number represents each character. This sound like a simple problem, but it’s actually very tricky, due to the number of different characters that are in use around the world.
Our desire to be able to encode all characters in all language is balanced by our need to be efficient. i.e. we want to use the least number of bytes per character that we’re storing.
In the early days of computing, we used US-ASCII as a standard, which stored each character in 7 bits (range of 0-127). Although it was sufficient for “standard” English language typewriter symbols, this is rarely used anymore since it cannot handle languages other than English, nor can it handle very many extra symbols.
The Unicode standard is used for modern encoding. Every character known is represented in Unicode, and requires one or more bytes to store (i.e. it’s a multibyte format). UTF-8 refers to unicode encoding for those characters which only require a single byte (the 8 refers to 8-bit encoding). UTF-16 and UTF-32 are used for characters that require 2 and 4 bytes respectively.
UTF-8 is considered standard encoding unless the data format required additional complexity.
Working with Files
Text
The Kotlin Standard Library (“kotlin-stdlib“) includes the standard IO functions for interacting with the console.
- readLine() reads a single value from “stdin“
- println() directs output to “stdout“
code/ucase.kts
// read single value from stdin
val str:String ?= readLine()
if (str != null) {
println(str.toUpperCase())
}
It also includes basic methods for reading from existing files.
import java.io.*
var filename = "transactions.txt"
// read up to 2GB as a string (incl. CRLF)
val contents = File(filename).readText(Charsets.UTF_8)
println(contents)
2020-06-06T14:35:44, 1001, 78.22, CDN
2020-06-06T14:38:18, 1002, 12.10, CDN
2020-06-06T14:42:51, 1003, 44.50, CDN
Example: rename utility
Let’s combine these ideas into a larger example.
Requirements: Write an interactive application that renames one or more files using options that the user provides. Options should support the following operations: add a prefix, add a suffix, or capitalize it.
We need to write a script that does the following:
- Extracts options and target filenames from the arguments.
- Checks that we have (a) valid arguments and (b) enough arguments to execute program properly (i.e. at least one filename and one rename option).
- For each file in the list, use the options to determine the new filename, and then rename the file.
Usage: rename.kts [option list] [filename]
For this example, we need to manipulate a file on the local file system. The Kotlin standard library offers a File class that supports this. (e.g. changing permissions, renaming the file).
Construct a ‘File‘ object by providing a filename, and it returns a reference to that file on disk.
fun main(args: Array<String>) {
val files = getFiles(args)
val options = getOptions(args)
// check minimum required arguments
if (files.size == 0 || options.size == 0) {
println("Usage: [options] [file]")
} else {
applyOptions(files, options)
}
fun getOptions(args:Array<String>): HashMap<String, String> {
var options = HashMap<String, String>()
for (arg in args) {
if (arg.contains(":")) {
val (key, value) = arg.split(":")
options.put(key, value)
}
}
return options
}
fun getFiles(args:Array<String>) : List<String> {
var files:MutableList<String> = mutableListOf()
for (arg in args) {
if (!arg.contains(":")) {
files.add(arg)
}
}
return files
}
fun applyOptions(files:List<String>,options:HashMap<String, String>) {
for (file in files) {
var rFile = file
// capitalize before adding prefix or suffix
if (options.contains("prefix")) rFile = options.get("prefix") + rFile
if (options.contains("suffix")) rFile = rFile + options.get("suffix")
File(file).renameTo(rFile)
println(file + " renamed to " + rFile)
}
}
Binary
These examples have all talked about reading/writing text data. What if I want to process binary data? Many binary data formats (e.g. JPEG) are defined by a standard, and will have library support for reading and writing them directly.
Kotlin also includes object-streams that support reading and writing binary data, including entire objects. You can, for instance, save an object and it’s state (serializing it) and then later load and restore it into memory (deserializing it).
class Emp(var name: String, var id:Int) : Serializable {}
var file = FileOutputStream("datafile")
var stream = ObjectOutputStream(file)
var ann = Emp(1001, "Anne Hathaway", "New York")
stream.writeObject(ann)
File Formats
A file format is a standard way of encoding data in a file. There are a large number of predefined file formats that have been designed and maintained by different standards bodies. If you are working with data that matches a predefined format, then you should use the correct file format for that data! Examples of standard file formats include HTML, Scalable vector graphics (SVG), MPEG video files, JPEG images, PDF documents and so on.
If you are working with your own data (e.g. our Customer data), then you are free to define your own encoding.
A fundamental distinction is whether you want text or binary encoding:
- Text encoding is storing data as a stream of characters in a standard encoding scheme (e.g. UTF8). Text files have the advantage of being human-readable, and can be easy to process and debug. However, for large amounts of data, they can also be slow to process.
- Binary encoding allows you to store data in a completely open and arbitrary way. It won’t be human-readable, but you can more easily store non-textual data in an efficient manner e.g. images from a drawing program.
Kotlin has libraries to support both. You can easily write a stream of characters to a text file, or push a stream of bytes to a binary file. We will explore how to do both in the next section.
A “rule of thumb” is that non-private data, especially if relatively small, should often be stored in a text file. The ability to read the file for debugging purposes is invaluable, as is the ability to edit the file in a standard text editor. This is why Preferences files, Log files and other similar data files are stored in human-readable formats.
Private data, or data that is difficult to process is probably better served in a binary format. It’s not human-readable, but that’s probably what you want if the data is sensitive. As we will discover, it can also be easier to process.
We know that we will use UTF-8, but that only describes how the characters will be stored. We also need to determine how to structure our data in a way that reflects our data model. We’ll talk about three different data structure formats for managing text data, all of which will work with UTF-8.
CSV
The simplest way to store records might be to use a CSV (comma-separated values) file.
We use this structure:
- Each row corresponds to one record (i.e. one object)
- The values in the row are the fields separated by commas.
For example, our transaction data file stored in a comma-delimited file would look like this:
1001, 2020-06-06T14:35:44, 78.22, CDN
1001, 2020-06-06T14:38:18, 12.10, USD
1002, 2020-06-06T14:42:51, 44.50, CDN
CSV is literally the simplest possible thing that we can do, and sometimes it’s good enough.
It has some advantages:
- it’s extremely easy to work with, since you can write a class to read/write it in a few lines of code.
- it’s human-readable which makes testing/debugging much easier.
- its fairly space efficient.
However, this comes with some pretty big disadvantages too:
- It doesn’t work very well if your data contains a delimiter (e.g. a comma).
- It assumes a fixed structure and doesn’t handle variable length records.
- It doesn’t work very well with complex or multidimensional data. e.g. a Customer class.
// how do you store this as CSV? the list is variable length
data class Customer(id:Int, name:String, transactions:List<Transactions>)
Data streams are used to provide support for reading and writing “primitives” from streams. They are very commonly used.
- File:
FileInputStream,FileOutputStream - Data:
DataInputStream,DataOutputStream
var file = FileOutputStream("hello.txt")
var stream = DataOutputStream(file)
stream.writeInt(100)
stream.writeFloat(2.3f)
stream.writeChar('c')
stream.writeBoolean(true)
We can use streams to write our transaction data to a file quite easily.
val filename = "transactions.txt"
val delimiter = "," // comma-delimited values
// add a new record to the data file
fun append(txID:Int, amount:Float, curr:String = "CDN") {
val datetime = LocalDateTime.now()
File(filename).appendText("$txID $delimiter $datetime $delimiter $amount\n", Charsets.UTF_8)
}
XML
XML (Extensible Markup Language) is a human-readable markup language that designed for data storage and transmission.
Defined by the World Wide Web Consortium’s XML specification, it was the first major standard for markup languages. It’s structurally similar to HTML, with a focus on data transmission (vs. presentation).
- Structure consists of pairs of tags that enclose data elements:
<name>Jeff</name> - Attributes can extend an element:
<img src="madonna.jpg"></img>
Example of a music collection structured in XML. An album is a record, and each album contains fields for title, artist etc.
<catalog>
<album>
<title>Empire Burlesque</title>
<artist>Bob Dylan</artist>
<country>USA</country>
<company>Columbia</company>
<price>10.90</price>
<year>1985</year>
</album>
<album>
<title>Innervisions</title>
<artist>Stevie Wonder</artist>
<country>US</country>
<company>The Record Plant</company>
<price>9.90</price>
<year>1973</year>
</album>
</catalog>
XML is useful, but doesn’t handle repeating structured particularly well. It’s also verbose when working with large amount of data. Finally, although it’s human-readable, it’s not particularly easy to read.
We’ll talk about processing XML in a moment. First, let’s talk about JSON.
YAML
Yaml (Yet Another Markup Language) is a human-readable data serialization format that is often used for configuration files and data exchange. It is a superset of JSON, and is designed to be easy to read and write.
YAML is a great choice for configuration files, because it is easy to read and write, and can be used to represent complex data structures.
input: .
output: .retype
url: https://student.cs.uwaterloo.ca/~cs346/1249
branding:
title: CS 346
label: F24
links:
- text: GitLab
icon: git-branch
link: https://git.uwaterloo.ca/cs346/public
- text: Piazza
icon: people
link: https://piazza.com/class/lv5da9i739r1hs
- text: Learn
icon: book
link: https://learn.uwaterloo.ca
YAML doesn’t handle nested structures well, but is great for simple data structures and configuration files where users are expected to manually make edits.
One limitation to using YAML is that it isn’t supported natively in Kotlin. To read/write YAML (without writing your own parser), you’ll need to use a library like Kaml.
TOML
TOML is a configuration file format that’s easy to read due to its simple syntax. It’s designed to be easy to read and write, and is often used for configuration files.
# Primitive Values
enable = true
initial_value = "string"
value = 0
# Tables (Hash tables or dictionaries)
[check_ticket]
infer_ticket = true
title_position = "start"
# Arrays of Tables
[commit_scope]
[[commit_scope.options]]
value = "app"
label = "Application"
[[commit_scope.options]]
value = "share"
label = "Shared"
[[commit_scope.options]]
value = "tool"
label = "Tools"
Like YAML, TOML isn’t supported natively in Kotlin. To read/write TOML (without writing your own parser), you’ll need to use a library like KToml.
JSON
JSON (JavaScript Object Notation) is an open standard file and data interchange format that’s commonly used on the web. It’s based on JavaScript object notation, but is language independent. It was standardized in 2013 as ECMA-404.
JSON has become extremely popular due to its simpler syntax compared to XML and other formats.
- Data elements consist of name/value pairs
- Fields are separated by commas
- Curly braces hold objects
- Square brackets hold arrays
Here’s the music collection in JSON.
{ "catalog": {
"albums": [
{
"title":"Empire Burlesque",
"artist":"Bob Dylan",
"country":"USA",
"company":"Columbia",
"price":"10.90",
"year":"1988"
},
{
"title":"Innervision",
"artist":"Stevie Wonder",
"country":"US",
"company":"The Record Plant",
"price":"9.90",
"year":"1973"
}
]
}}
Advantages of JSON:
- Simplifying closing tags makes JSON easier to read.
{ "employees":[
{ "first":"John", "last":"Zhang", "dept":"Sales"},
{ "first":"Anna", "last":"Smith", "dept":"Engineering"}
]}
Compare this to the corresponding XML:
<employees>
<employee><first>John</first> <last>Zhang</last> <dept>Sales</dept></employee>
<employee><first>Anna</first> <last>Smith</last> <dept>Engineering</dept></employee>
</employees>
- JSON also handles arrays better.
Array in XML:
<record>
<name>Celia</name>
<age>30</age>
<cars>
<model>Ford</model>
<model>BMW</model>
<model>Fiat</model>
</cars>
</record>
Array in JSON:
{
"name":"Celia",
"age":30,
"cars":[ "Ford", "BMW", "Fiat" ]
}
JSON is a great choice for data that is going to be shared between different systems, or for data that is going to be stored in a file. It’s easy to read, easy to write, and easy to parse.
Serialization
So, our application data resides in data structures, in memory. If we want to save them using these data formats, we need to convert objects to the appropriate format.
- To save: we convert objects into XML or JSON format, then save the raw XML or JSON in a data file.
- To restore: we load XML or JSON from our data files, and instantiate objects (records) based on the file contents.
Although you could write your own conversion function/parser, there are a number of libraries out there than handle conversion to and from JSON quite easily.
We’ll focus on using Kotlin’s serialization libraries to convert our objects to and from JSON directly!
Serialization is the process of converting your program to a binary stream, so that you can transmit it, or persist it to a file or database. Deserialization is the process of converting the stream back into an object.
This is really cool technology that we can use to save our objects directly without trying to save the individual property values (like we would for a CSV file).
To include the serialization libraries in your project, add these dependencies to the build.gradle.kts file.
plugins {
id 'org.jetbrains.kotlin.multiplatform' version '1.6.10'
id 'org.jetbrains.kotlin.plugin.serialization' version '1.6.10'
}
Also make sure to add the dependency:
dependencies {
implementation "org.jetbrains.kotlinx:kotlinx-serialization-json:1.3.2"
}
You can then save your objects directly as a stream which you can save to a file, or a database. You can later use this stream to recreate your objects. See https://github.com/Kotlin/kotlinx.serialization for details.
Example from: https://blog.jetbrains.com/kotlin/2020/10/kotlinx-serialization-1-0-released/
@Serializable
data class Project(
val name: String,
val owner: Account,
val group: String = "R&D"
)
@Serializable
data class Account(val userName: String)
val moonshot = Project("Moonshot", Account("Jane"))
val cleanup = Project("Cleanup", Account("Mike"), "Maintenance")
fun main() {
val string = Json.encodeToString(listOf(moonshot, cleanup))
println(string)
// [{"name":"Moonshot","owner":{"userName":"Jane"}},{"name":"Cleanup","owner":
// {"userName":"Mike"},"group":"Maintenance"}]
val projectCollection = Json.decodeFromString<List<Project>>(string)
println(projectCollection)
// [Project(name=Moonshot, owner=Account(userName=Jane), group=R&D),
// Project(name=Cleanup, owner=Account(userName=Mike), group=Maintenance)]
}
Note that to make this work, you have to annotate your class as @Serializable. It also needs to contain data that can be converted to JSON.