Assignments
Data-Intensive Distributed Computing (Fall 2021)
Assignment 4: Multi-Source Personalized PageRank due 4:00 pm November 5
For this assignment, you will be working in the same repo as
before, except that everything should go into the package namespace
ca.uwaterloo.cs451.a4.
Begin by taking the time to understand
the PageRank
reference implementation in Bespin
(particularly RunPageRankBasic). For this assignment,
you are going to implement multiple-source personalized PageRank. As
we discussed in class, personalized PageRank is different from
ordinary PageRank in a few respects:
- There is the notion of a source nodes, which is what we're computing the personalization with respect to.
- When initializing PageRank, instead of a uniform distribution across all nodes, the m source nodes get a mass of 1/m and every other node gets a mass of zero.
- Whenever the model makes a random jump (or jumps out of a dangling node), the random jump is always back to one of the source nodes randomly (i.e., 1/m probablity to one of the source nodes); this is unlike in ordinary PageRank, where there is an equal probability of jumping to any node.
The following animation illustrates how multi-source personalized pagerank works. In this example, e and a are source nodes.
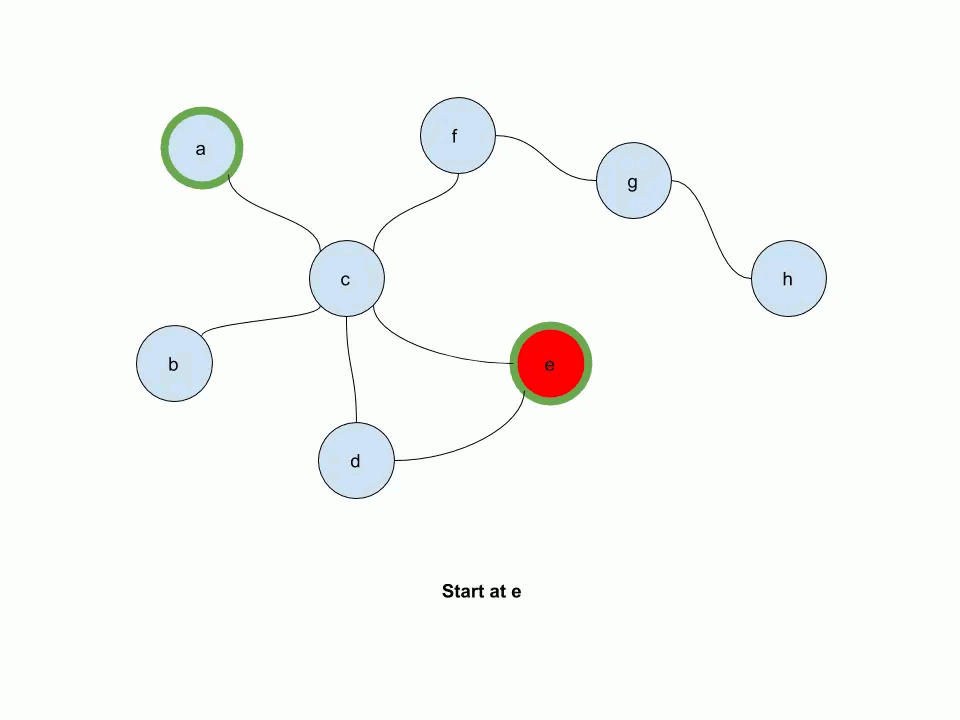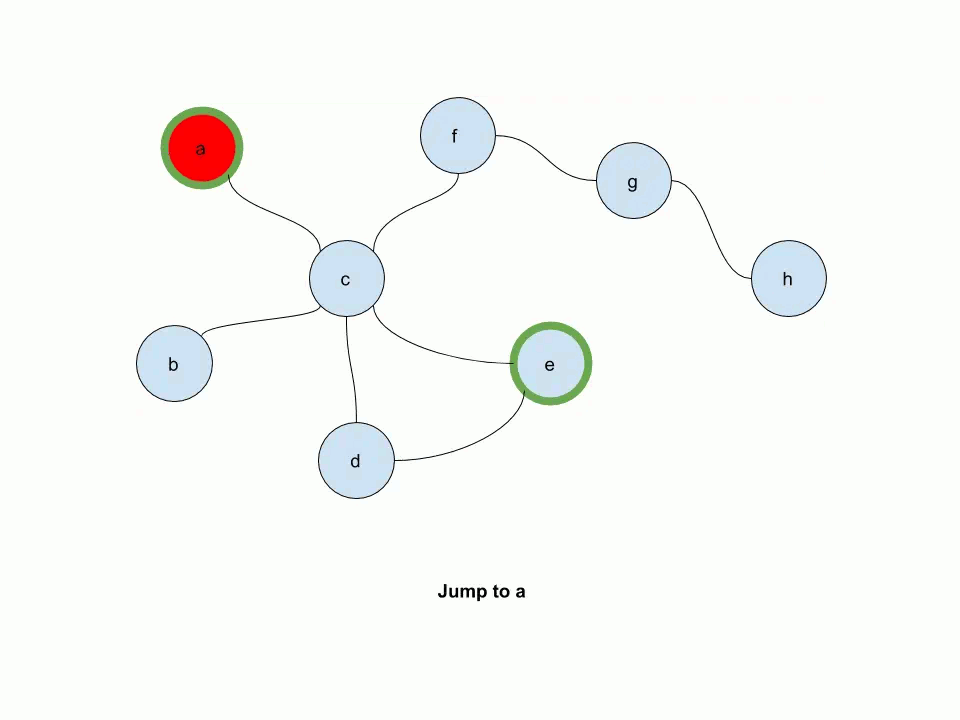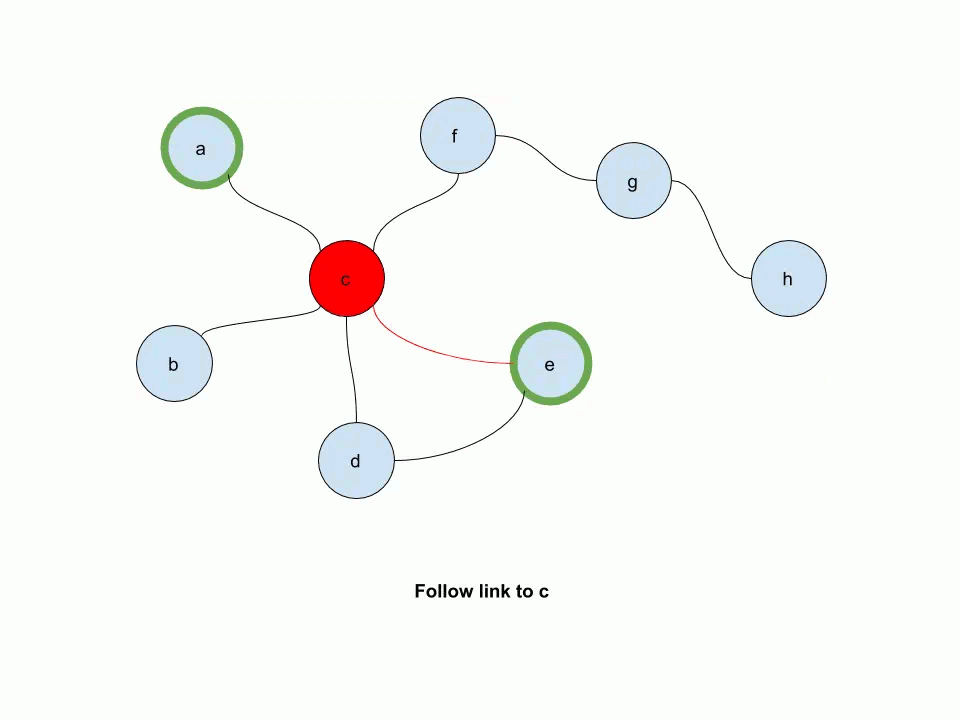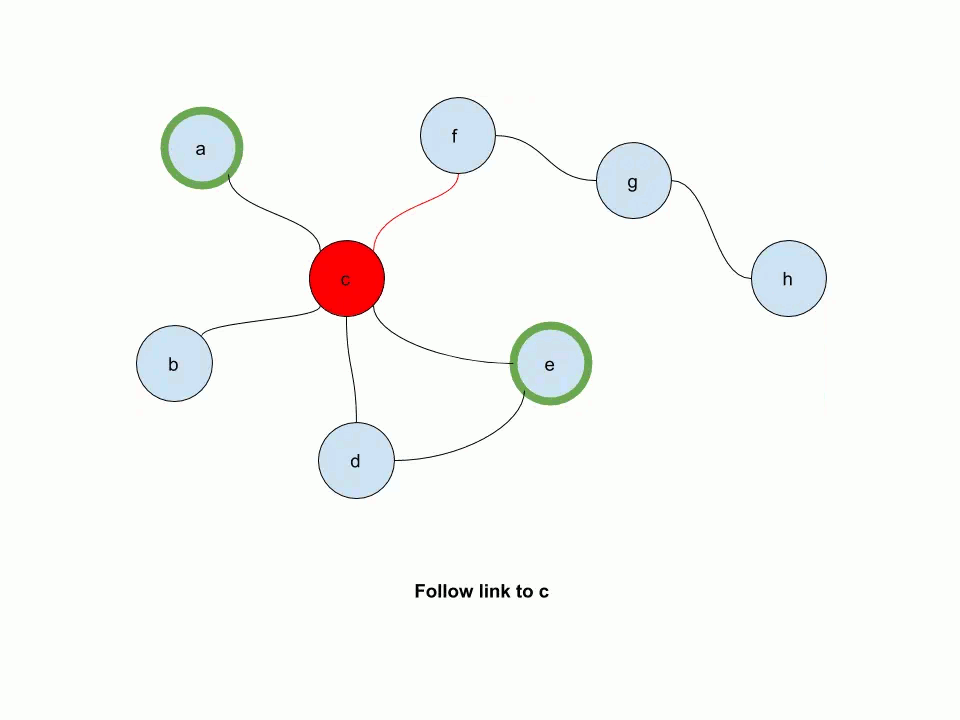
Start by working with the Gnutella graph
(a snapshot
of the Gnutella peer-to-peer file sharing network from August 2002),
the same as the one used in the Bespin demo. Copy data/p2p-Gnutella08-adj.txt from Bespin to your repository.
Here's how the implementation is going to work: it roughly follows
the reference implementation of RunPageRankBasic. You
must make your implementation work with respect to the command-line
invocations specified below.
First, convert the adjacency list into PageRank node records. Change BuildPageRankRecords to initialize the graph based on Personalized PageRank
$ hadoop jar target/assignments-1.0.jar \ ca.uwaterloo.cs451.a4.BuildPersonalizedPageRankRecords \ -input data/p2p-Gnutella08-adj.txt -output cs451-bigdatateach-a4-Gnutella-PageRankRecords \ -numNodes 6301 -sources 367,249,145
The -sources option specifies the source nodes for the
personalized PageRank computations. You can expect the option value to be in the form of a
comma-separated list, and that all node ids actually exist in the
graph. The list of source nodes may be arbitrarily long, but for
practical purposes we won't test your code with more than a few.
Here, we're running twenty iterations.
Next, partition the graph (hash partitioning) and get ready to
iterate. Simply copy PartitionGraph from Bespin. No change is needed.
$ hadoop fs -mkdir cs451-bigdatateach-a4-Gnutella-PageRank $ hadoop jar target/assignments-1.0.jar \ ca.uwaterloo.cs451.a4.PartitionGraph \ -input cs451-bigdatateach-a4-Gnutella-PageRankRecords \ -output cs451-bigdatateach-a4-Gnutella-PageRank/iter0000 -numPartitions 5 -numNodes 6301
After setting everything up, iterate multi-source personalized PageRank:
$ hadoop jar target/assignments-1.0.jar \ ca.uwaterloo.cs451.a4.RunPersonalizedPageRankBasic \ -base cs451-bigdatateach-a4-Gnutella-PageRank -numNodes 6301 -start 0 -end 20 -sources 367,249,145
Important requirement: Unlike the Bespin implementation that calculates pagerank scores in two phases, your program must calculate personalized pagerank in only one phase (i.e., one MapReduce job). This includes taking care of random walk, jumping factor, and dangling nodes. Therefore, you cannot calculate the missing probability and add it back to the source nodes. Instead, your code must work in a way that jumping from dangling nodes is handled directly rather than adding the leaked probability back to the source nodes. Obviously, you still need multiple iterations of this phase to converge.
Finally, run a program to extract the top ten personalized PageRank values. Copy this program from Bespin to your repository and modify it to produce the desired output.
$ hadoop jar target/assignments-1.0.jar \ ca.uwaterloo.cs451.a4.FindMaxPageRankNodes \ -input cs451-bigdatateach-a4-Gnutella-PageRank/iter0020 -output cs451-bigdatateach-a4-Gnutella-PageRank-top10 \ -top 10
If the set of source nodes includes 367,249, and 145, the above program should write the following answer to cs451-<YOUR USERID>-a4-Gnutella-PageRank-top10/part-r-00000
0.13300 367 0.12234 145 0.12140 249 0.02720 1317 0.01747 264 0.01628 266 0.01615 559 0.01610 5 0.01579 7 0.01507 251
Additional Specifications
To make the final output easier to read, in the
class FindMaxPageRankNodes, use the
following format to write each (personalized PageRank value, node id)
pair:
String.format("%.5f %d", pagerank, nodeid)
This will generate the final results in the same format as above. Also note: write actual probabilities, not log probabilities—although during the actual PageRank computation keep values as log probabilities.
The final class FindMaxPageRankNodes
does not need to be a MapReduce job (but it does need to read from
HDFS). Obviously, the other classes need to run MapReduce jobs.
The reference implementation of PageRank in Bespin has many options such as in-mapper combining and ordinary combiners. In your implementation, use ordinary combiners. Also, the reference implementation has an option to either use range partitioning or hash partitioning: you only need to implement hash partitioning. You can start with the reference implementation and remove code that you don't need.
Hints and Suggestion
To help you out, there's a small helper program in Bespin that computes personalized PageRank using a sequential algorithm. Copy it to your repository and use it to check your answers:
$ hadoop jar target/assignments-1.0.jar ca.uwaterloo.cs451.a4.SequentialPersonalizedPageRank \ -input data/p2p-Gnutella08-adj.txt -sources 367,249,145
Note that this isn't actually a MapReduce job; we're simply using
Hadoop to run the main for convenience. The values from
your implementation should be pretty close to the output of the above
program, but might differ a bit due to convergence issues. After 20
iterations, the output of the MapReduce implementation should match to
at least the fourth decimal place.
Make sure your program does not produce NaN (might happen due to float precision problem). You should be doing computations using log probabilities to minimize issues with float precision error.
Running on the Datasci cluster
Once you get your implementation working and debugged in the student Linux
environment, you're going to run your code on a non-trivial graph: the
link structure of (all of) Wikipedia. The adjacency lists are stored
in /data/cs451/enwiki-20180901-adj.txt in HDFS on the Datasci cluster.
The graph has 14,099,242 vertices and 117,394,777 edges.
First, convert the adjacency list into PageRank node records:
$ hadoop jar target/assignments-1.0.jar \ ca.uwaterloo.cs451.a4.BuildPersonalizedPageRankRecords \ -input /data/cs451/enwiki-20180901-adj.txt -output cs451-bigdatateach-a4-wiki-PageRankRecords \ -numNodes 14099242 -sources 73273,73276
Next, partition the graph (hash partitioning) and get ready to iterate:
$ hadoop fs -mkdir cs451-bigdatateach-a4-wiki-PageRank $ hadoop jar target/assignments-1.0.jar \ ca.uwaterloo.cs451.a4.PartitionGraph \ -input cs451-bigdatateach-a4-wiki-PageRankRecords \ -output cs451-bigdatateach-a4-wiki-PageRank/iter0000 -numPartitions 10 -numNodes 14099242
After setting everything up, iterate multi-source personalized PageRank:
$ hadoop jar target/assignments-1.0.jar \ ca.uwaterloo.cs451.a4.RunPersonalizedPageRankBasic \ -base cs451-bigdatateach-a4-wiki-PageRank -numNodes 14099242 -start 0 -end 20 -sources 73273,73276
On the Datasci cluster, each iteration shouldn't take more than a couple of minutes to complete. If it's taking more than five minutes per iteration, you're doing something wrong.
Finally, run a program to extract the top ten personalized PageRank values.
$ hadoop jar target/assignments-1.0.jar \ ca.uwaterloo.cs451.a4.FindMaxPageRankNodes \ -input cs451-bigdatateach-a4-wiki-PageRank/iter0020 -output cs451-bigdatateach-a4-wiki-PageRank-top10 \ -top 10
In the example above, we're running personalized PageRank with
respect to two sources: 73273 and 73276. What articles do these ids
correspond to? There's a file on HDFS
at /data/cs451/enwiki-20180901-titles.txt that provides the
answer. How do you know if your implementation is correct? You can
sanity check your results by taking the ids and looking up the
articles that they correspond to. Do the results make sense?
Here is the expected output for these source nodes.
The output must go to cs451-<YOUR USERID>-a4-wiki-PageRank-top10/part-r-00000 on HDFS.
0.08205 73276 0.08193 73273 0.00353 22218 0.00303 5042916 0.00241 259124 0.00196 89585 0.00133 20798 0.00132 342663 0.00131 178880 0.00128 3434750
Turning in the Assignment
Please follow these instructions carefully!
Make sure your repo has the following item:
- All the implementations described above should be in
package
ca.uwaterloo.cs451.a4.
Make sure your implementation runs in the Linux student CS environment on the Gnutella graph and on the Wikipedia graph on the Datasci cluster.
When grading, we will clone your repo and use the below check scripts:
check_assignment4_public_linux.pyin the Linux Student CS environment.check_assignment4_public_datasci.pyon the Datasci cluster.
When you've done everything, commit to your repo and remember to push back to origin. You should be able to see your edits in the web interface. Before you consider the assignment "complete", we would recommend that you verify everything above works by performing a clean clone of your repo and running the public check scripts.
That's it!
Grading
The entire assignment is worth 55 points:
- A correct implementation of multiple-source personalized PageRank is worth 25 points.
- That we are able to run the multiple-source personalized PageRank implementation in the Linux Student CS environment is worth 10 points.
- Scaling the multiple-source personalized PageRank implementation on the Datasci cluster is worth 20 points.
In our private check scripts, we will specify arbitrary source nodes to verify the correctness of your implementation.
Note that this grading scheme discretizes each component of the assignment. For example, if you implement everything and it works correctly on the Linux Student CS environment, but can't get it to scale on the Datasci cluster to the larger graph, you'll receive 35 out of 55 points.
Reference Running Times
To help you gauge the efficiency of your solution, we are giving you the running times of our reference implementations. Keep in mind that these are machine dependent and can vary depending on the server/cluster load.
| Class name | Running time Linux | Running time Datasci |
|---|---|---|
| BuildPersonalizedPageRankRecords | 15 seconds | 2 minutes |
| PartitionGraph | 15 seconds | 2 minutes 30 seconds |
| RunPersonalizedPageRankBasic | 75 seconds (20 iterations) | 30 minutes (20 iterations) |
| FindMaxPageRankNodes | 15 seconds | 45 seconds |