Assignments
Data-Intensive Distributed Computing (Winter 2026)
Assignment 4: PageRank and Multi-Source Personalized PageRank Due: 4:00pm Mar. 11.
For this assignment, you will be working in the same repo as
before, except that everything should go into the package namespace
ca.uwaterloo.cs451.a4.
Begin by taking the time to understand the PageRank reference implementation in the Apache Spark repository. For this assignment, you are going to modify this code to handle dead-ends efficiently. Then you will implement multiple-source personalized PageRank.
Start by working with the Gnutella graph
(a snapshot
of the Gnutella peer-to-peer file sharing network from August 2002),
the same as the one used in the Bespin demo. Copy data/p2p-Gnutella08-adj.txt from Bespin to your repository.
Modify PageRank
I've started your work for you! Download PageRank.scala and place it into your assignments repository (in the appropriate directory within src).
This is essentially the same code from Apache, but I've changed it so the ranks sum to 1 as we did in class, instead of summing to N.
However, if we try this with our input files, it won't work for a few reasons:
- The input file in the Apache example is an edge-list format. Each line is a node label, whitespace, and then an out-neigbour label. Our input files will be adjacency lists. Each line is a whitespace separated list of labels. The first label is a node, and the next labels (if any) are its adjacency list. For example the line "0 1 2 3 4 5" means "Node 0 has the adjacency list [1,2,3,4,5]". You'll need to modify the map that creates the adjacency list RDD.
- Tip: be sure the adjacency list is partitioned by key still, or the join will perform a shuffle. This is quite slow.
- The Apache example assumes that there are no dead-end nodes. In our input files there are many dead-end nodes so this is a poor assumption. You will need to find a way to compute the missing mass and correctly add it back into the system.
(Note: You should assume that the number of dead-ends is O(n), so having them send contributions to the entire graph will be adding O(n^2) messages! That's far too many and you will NOT get the marks for your datasci component as it will certainly time out).
- You might use a
reduceaction to compute the sum of all ranks, and subtract that from 1 to find the amount missing. - You might also write into an accumulator as you go, though note that you will still need an action before you can read from that accumulator, so there's not much difference.
- In either case, be sure to appropriately cache RDDs to avoid repeating shuffles. Don't forget to unpersist them after or you may run low on memory.
- You might use a
There is one last change you should make: After the required number of iterations has passed, you should print top 20 nodes and their ranks. The required format is "{id}\t{rank}\n" - in other words, the node's identifier, a tab character, the node's page rank, and then a newline. You must not use collect and then sort the results on the driver. There are a few actions that might help you here, explore the RDD API. (And please don't spoil it for the rest of the class when you find the way. Exploration is part of learning!)
With those changes, you should be able to run your code.
$ spark-submit --class ca.uwaterloo.cs451.a4.PageRank target/assignments-1.0.jar\
--input data/p2p-Gnutella08-adj.txt\
--output gnutella-page-rank-20itr\
--iterations 20
If you've done everything right, this should only take a few seconds, and then print the top 20 nodes. Here are the first 5 for your reference.
367 0.0023879095 249 0.0021844946 145 0.0020551141 264 0.0019989882 266 0.001963612As with previous assignments, remember that floating point numbers are inexact so you do not need to match the output exactly. The marking scripts will consider the results correct if they match when rounded to 5 digits after the decimal place. (That doesn't mean you should do the rounding! It means if only the last digit differs from the sample output, you're fine!)
Once you get your implementation working and debugged in the student Linux
environment, you're going to run your code on a non-trivial graph: the
link structure of (all of) Wikipedia. The adjacency lists are stored
in /data/cs451/enwiki-20180901-adj.txt in HDFS on the Datasci cluster.
The graph has 14,099,242 vertices and 117,394,777 edges.
$ spark-submit --class ca.uwaterloo.cs451.a4.PageRank\
--num-executors 2 --executor-cores 4 --executor-memory 24G\
target/assignments-1.0.jar\
--input /data/cs451/enwiki-20180901-adj.txt\
--output wiki-page-rank-20itr\
--iterations 20\
--partitions 8
This will take a while longer! (~10 minutes is about what's expected - if you're taking more than 15 minutes you might have some efficiency issues. If you're taking more than 24 then you definitely do). If you're having efficiency issues set iterations to a smaller number as you attempt to make your code faster. There's no need to run all 20 of them, I am begging you!
3434750 0.0012662816 10568 8.5438526E-4 32927 7.9449476E-4 5843419 6.8865827E-4 273285 6.2089064E-4Uh oh, those values are quite a bit smaller! That's to be expected. For bigger graphs there would be too much instability and we'd want to switch to log-masses instead, but for this graph it'll still be accurate to 4 or so digits of precision. For example, we can see that the top node has page rank 0.0012662816 when using
Float, which is 32-bit. Switching to 128-bit floating point numbers gives us: 0.00126627953957204720031841570725643467704. While this number is more accurate, we can see that the Float version isn't terrible, and the high precision version uses 4x the data during a shuffle!
Personalized PageRank
Next, copy yourPageRank.scala file to PersonalizedPageRank.scala
Personalized PageRank is similar to regular PageRank, with a few important differences:
- There is the notion of a source nodes, which is what we're computing the personalization with respect to.
- When initializing PageRank, instead of a uniform distribution across all nodes, the m source nodes get a mass of 1/m and every other node gets a mass of zero.
- Whenever the model makes a random jump (or jumps out of a dangling node), the random jump is always back to one of the source nodes randomly (i.e., 1/m probability to one of the source nodes); this is unlike in ordinary PageRank, where there is an equal probability of jumping to any node.
The following animation illustrates how multi-source personalized pagerank works. In this example, e and a are source nodes.
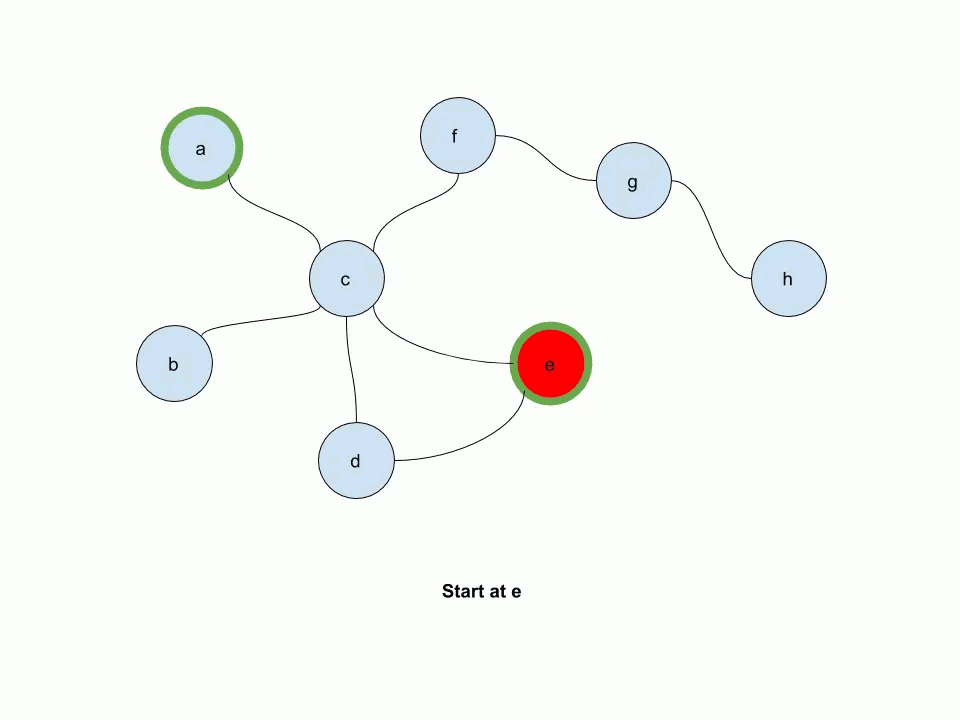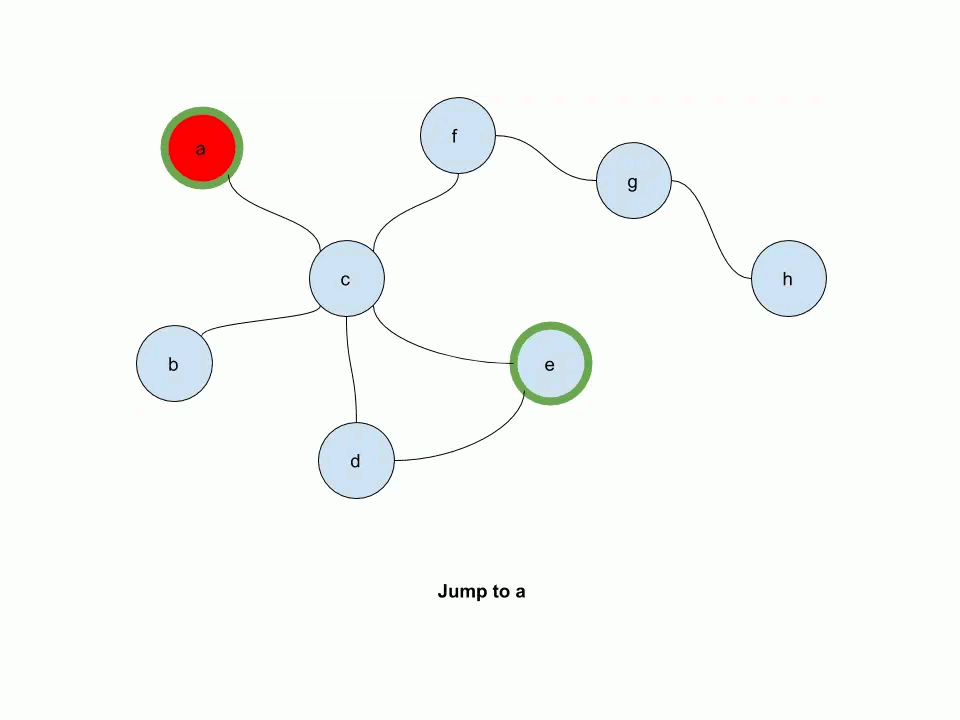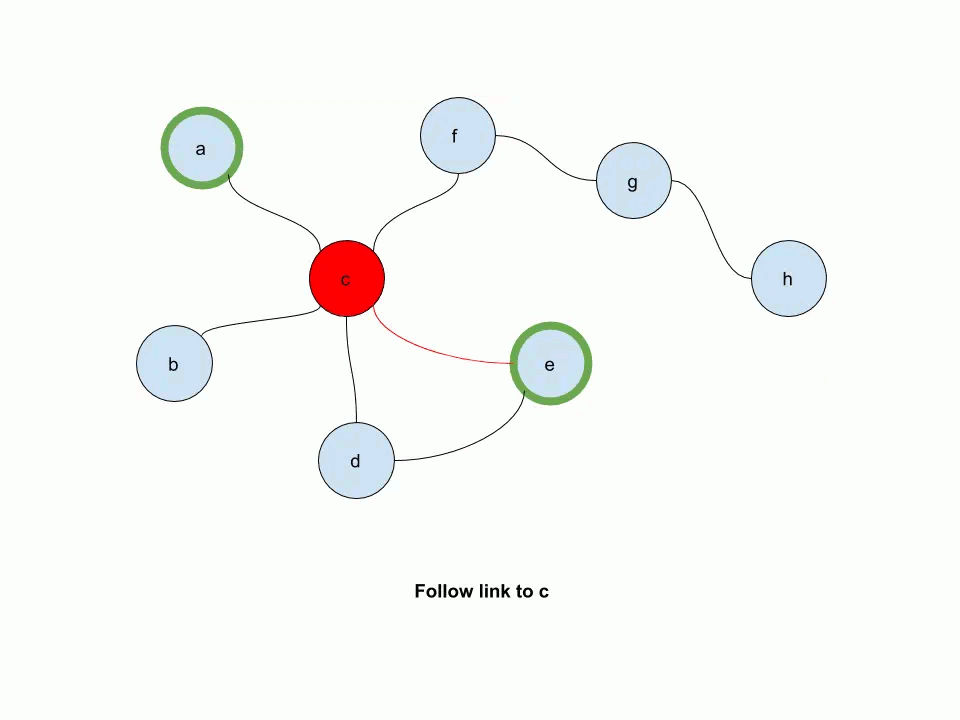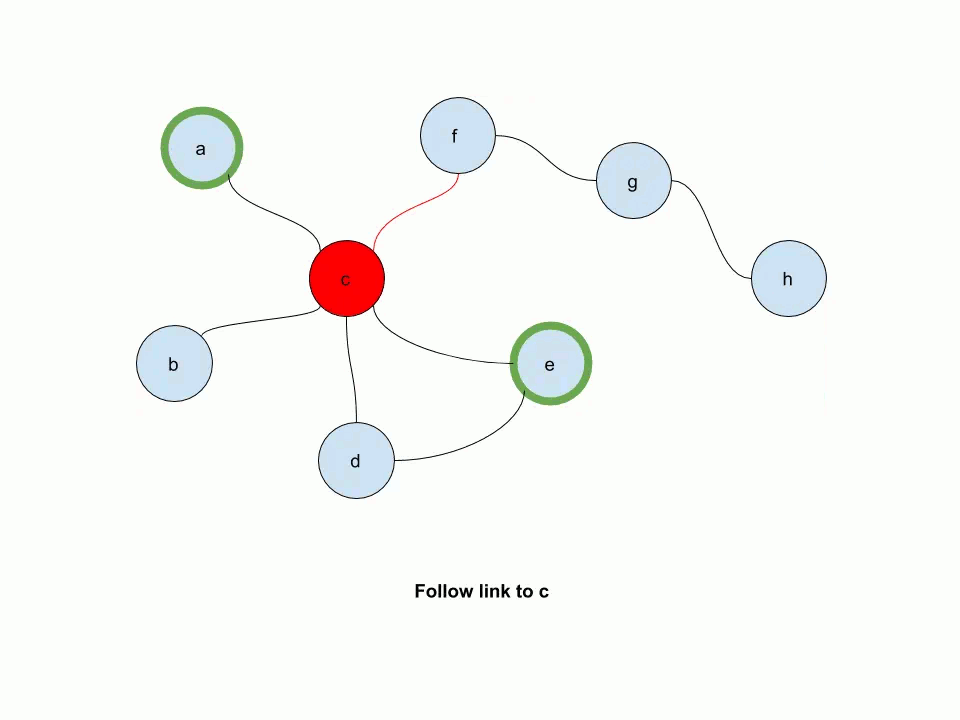 -- keep in mind that we're not simulating the random walk, but computing the probability distribution for the random walk!
-- keep in mind that we're not simulating the random walk, but computing the probability distribution for the random walk!
The first change you should make to your program is the addition of a --sources argument. In Scallop you can specify the type as opt[List[Int]] and it will collect all numbers after the flag into this parameter. This parameter should be required and you can assume it will be a non-empty list (you do not need to check).
Warning: Scallop objects are not serializable. If you get "task not serializable" you probably have referred to args.sources() in one of the functions passed in to Spark. Just make a List variable for this value. You can assume it's a short list so a broadcast variable isn't necessary (but it's fine if you use one).
Now that your program can take the --sources argument, you should change how page ranks are computed. Note: Since nodes with a mass of 0 will be sending 0 along their links, you don't actually need them! So you might decide to have your ranks RDD only contain the source nodes initially. However if you do this make sure you do not "forget" about any nodes. (I will not elaborate on what this means!)
Next you should change the "update" portion of your code so that the "jump" mass only gets added to source nodes. Note that you can no longer use mapValues as the behaviour now depends on the node ID! But be careful, map breaks the partitioning of an RDD because Spark does not know whether you have changed the keys. You instead should use mapPartitions which has an optional second argument preservesPartitioning. Set that to true. As with A2 you should be using a custom iterator to reduce memory overhead (the good news is that this custom iterator is trivial -- we're not using it because we need to preserve state between items, but because map doesn't have the option to preserve partitioning). If you use map you will end up doing two shuffles per iteration and may timeout on datasci.
Final note - you can assume the number of source nodes is very small, so unlike with regular PageRank it's reasonable to have dead-ends send messages directly to the source nodes. This way there is no missing mass to calculate.
Let's start by using the top 3 PageRank nodes as our source nodes.
$ spark-submit --class ca.uwaterloo.cs451.a4.PersonalizedPageRank target/assignments-1.0.jar\
--input data/p2p-Gnutella08-adj.txt\
--output gnutella-page-rank-20itr\
--iterations 20\
--sources 367 249 145
This should take roughly the same amount of time as the regular PageRank version.
The source nodes should still be the top 3. And since the jump factor of 0.15 (or rather, the damping factor if 0.85) the source nodes cannot possibly have less than 0.05 rank each. (And in fact will have a fair bit more than that).
367 0.13300167 145 0.1223405 249 0.12139854 1317 0.027197745 264 0.01746714Again, that's clearly not all 20 of them, but should give you an idea of the expected values. Note the large drop between the source nodes and the next highest rank nodes.
Debugging tip: If your numbers are way off, let's figure out why! Consider using 0 as the source node, and only doing 1 iteration. Look at the first line of the input file. How many neighbours does it have? What are they? If there are k of them, they should all have the same rank: 1.0 / k * 0.85. Since 0 does not link to itself, its rank will be 0.15 (just the random jumps). If that's correct then you're handling regular nodes correctly. Probably. So do 2 iterations. I'll make you do the math yourselves. Again, once you have it working for a small graph, we're going to move to the cluster and try it out on a substantial graph.
$ spark-submit --class ca.uwaterloo.cs451.a4.PersonalizedPageRank\
--num-executors 2 --executor-cores 4 --executor-memory 24G\
target/assignments-1.0.jar\
--input /data/cs451/enwiki-20180901-adj.txt\
--output wiki-personalized-page-rank-20itr\
--iterations 20\
--partitions 8\
--sources 73273 73276
Depending how you handled things this might be a bit faster than regular PageRank as not all nodes are "active" for the first few iterations. But by the end each iteration should be taking about the same amount of time as it did with regular PageRank
Here are the expected top 5 (your program should be printing the top 20, I'm just truncating).
73276 0.082051165 73273 0.08193028 22218 0.0035292057 5042916 0.0030340347 259124 0.0024140715
Checking your programs
To make sure your code runs correctly, use the following public check script: check_assignment4_public.py Note that this time around there's only one script, it will detect if it's on datasci or not. (So it will run on your own machines too, with the same inputs as student.cs). This has some extra command line parameters. You can control the number of iterations with-i, which defaults to 20. You can also choose to run only one question using -q 1 to run just PageRank or -q 2 to run just PersonalizedPageRank. You can also pick different source nodes for PersonalizedPageRank using -s 1 2 3 4 (Just as an example, that would use nodes 1, 2, 3, and 4 as source nodes) - by default it uses the same source nodes as shown above, which will depend on which system you run it on.
Note that it passes your programs stdout through grep to find the output that matches the required format, and uses head to limit this to 5 matches. If you get output that's not part of the top 20 nodes, get rid of those prints (use the logger instead). If you get no output, check that you're following the required format (in particular, make sure you're using the tab character!)
Turning in the Assignment
Please follow these instructions carefully!
Make sure your repo has the following item:
- All the implementations described above should be in
package
ca.uwaterloo.cs451.a4.
Make sure your implementation runs in the Linux student CS environment on the Gnutella graph and on the Wikipedia graph on the Datasci cluster.
When you've done everything, commit to your repo and remember to push back to origin. You should be able to see your edits in the web interface. Before you consider the assignment "complete", we would recommend that you verify everything above works by performing a clean clone of your repo and running the public check scripts.
That's it!
Grading
The entire assignment is worth 40 points:
- A correct PageRank implementation is worth 10 marks if it runs on student.cs, and an additional 10 if it also works on datasci
- A correct PersonalizedPageRank implementation is worth 10 marks if it runs on student.cs, and an additional 10 if it also works on datasci.
- The private test scripts will be checking the "top 20" output as well the contents of the output files - but most marks will be for the top 20 nodes.
- For peronalized PageRank we will perform multiple runs with different sets of source nodes.
- Correct output is not all-or-nothing - if you have the right top 20 nodes but some have incorrect ranks, you will lose some marks but not all.
- If your program's output is completely incorrect but it does generate output with the correct format, that is worth 1 mark.
- As with previous assignments, we will be rounding to 5 digits after the decimal place when checking if floating point values are equal. If you only match to 4 digits there will be part marks awarded since you were close!
- Every approach I've tried has matched every other to 6+ digits.
Reference Running Times
To help you gauge the efficiency of your solution, we are giving you the running times of our reference implementations. Keep in mind that these are machine dependent and can vary depending on the server/cluster load. The student.cs times are given according to the "task finished" timer, so they do not include startup time which can sometimes be lengthy.
| Class name | Running time Linux | Running time Datasci |
|---|---|---|
| PageRank (20 iterations) | 15 seconds | 10 minutes (25~30 seconds per iteration, plus start-up time) |
| PersonalizedPageRank (20 iterations, 2-3 sources) | 15 seconds | 7-8 minutes (may start at only a few seconds per iteration but after a few iterations should still be 20~25 s/it) |