Architectural styles
Let’s think about the features that every software application needs to support. Are there specific structural requirements that applications need to support?
Requirements
User interaction
Applications are interactive. Fundamentally, they revolve around an interaction cycle between the user and the system:
- The system launches and waits for user input.
- The user provides some input e.g., presses keys on a keyboard, moves a mouse, swipes on a screen.
- The system processes that input.
- The results e.g., output are displayed for the user.
The cycle looks something like this:

This loop is effectively the same across all interactive applications, including desktop, mobile and even console applications.
- Users perform actions with the user interface e.g., enter a command, tap/swipe on a phone, point/click with a mouse.
- The application responds to those user actions, by performing some computation, or fetching data or whatever else needs to be done.
- The results need to be sent back to the user interface to be displayed as output. This can be graphical, text, audio or any other suitable response that communications the result to the user.
We could model this simple interaction cycle as two components: one representing the user’s input-output and the second as the system that is interacting with them. Communication between them is done using events: messages between these componets to represent either the user’s input, or the system’s output to display. This works fine for simple systems.
Multiple sources
However, systems are rarely this simple. We often have multiple sources of data, and multiple sources of input that we need to manage.
In addition to the user interaction cycle (above), we can also have other events:
- The operating system may send events to your application that are not triggered by a user action. e.g., a timer ticking to indicate that time has elapsed, or a notification being sent to your application from some other service.
- Your application might request data (from a database of web service) which arrives after some delay. e.g., scrolling through a list of images that are on a remote site, while the list continues to populate in the background.
- Interruptions to your applications workflow based on some other high priority event. e.g., receiving a phone call while watching a video, and the phone call “forces itself” to the foreground.
A simple interaction cycle doesn’t handle these scenarios very well. We need to consider a more robust model that can address data coming in from other sources.
(resizing the window) and system events (the
clock hand moving every second).
When discussing situations like this, we often differentiate between control-flow vs. data-flow in an application.
- Control-flow refers to the path of execution: the order in which functions are called, code is executed and so on. In an event-based architecture, this is often the path that events take to flow through the system.
- Data-flow refers to the path through which data flows through the system, typically from some data source to a user-viewable output.
Architectural styles
How can you structure code to support these types of requirements?
In the same way that software developers use design patterns to describe useful and recurring software patterns, we use architectural styles to describe standard ways of structuring your code. There are a large number of architectural styles. In this course, we will focus on the subset of patterns that are most commonly used in building applications1.
{kind=link}
I highly recommend taking CS 446 as a followup course; it introduces many of these styles.
Model-View-Controller (MVC)
Model-View-Controller (MVC) was created by Trygve Reenskaug for Smalltalk-79 in the late 1970s as a method of structuring interactive applications. It suggests that an application should consist of the following components:
Model: the information or program state that you are working with,View: the visual representation of the model, andController: which lays out and coordinates multiple views on-screen, and handles routing user-input.
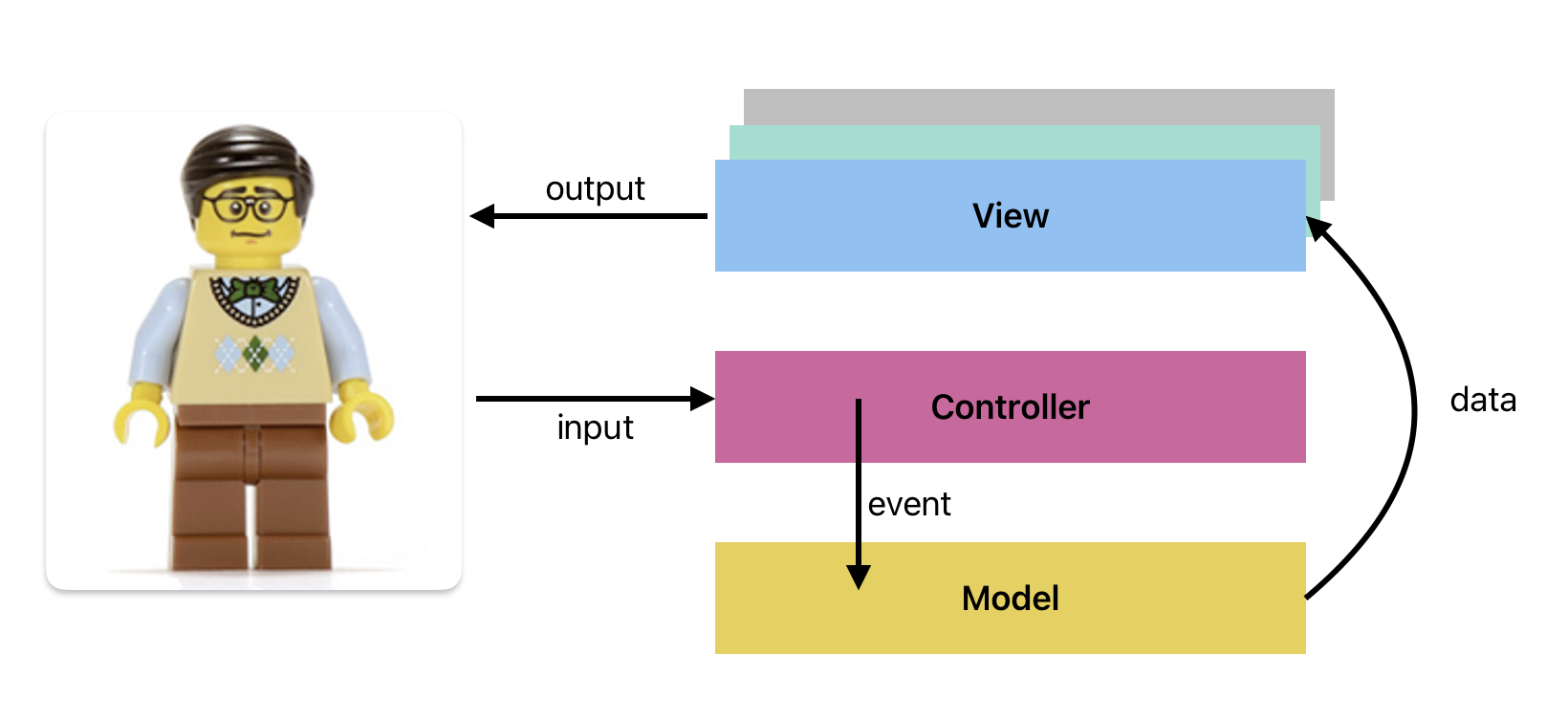
In a “standard MVC” implementation, input is accepted and interpreted by the Controller class, and routed to the Model, where it changes the program state (in some meaningful way). These changes are published to the View through a notification system so that the changes can be reflected to the user.
MVC is probably the most commonly used (and most heavily reworked) architectural pattern, having been used in web development since the 1990s. Many application frameworks e.g., Java Swing have adapted it as their underlying UI model.
Here’s a simple MVC implementation, using the Observer pattern for Model/View notifications. The model implements the Publisher interface, and each View is a Subscriber. There can be more than one View (just as there can be more than one UI screen) and each one can receive a notification when the state changes. The View ultimately determines how to output the results.
classDiagram
View "1" --> "1" Controller
Controller "1" --> "1" Model
Subscriber "1" <|.. "1" View
Publisher <|.. Model
Subscriber "*" <-- "*" Publisher
class View {
data: Data
+display(data)
}
class Controller {
view: View
model: Model
+invoke(event)
}
class Model {
data: Data
+sort(data)
}
class Subscriber {
<<Interface>>
+update()
}
class Publisher {
<<Interface>>
List~Subscriber~ subscribers
-notify()
}
However, there are a few challenges when implementing this version of MVC.
- Graphical user interfaces bundle the input and output together into graphical “widgets” on-screen (which we will explore further in the user interfaces section). This makes input and output behaviours difficult to separate, so in-practice, the controller class is rarely implemented.
- Modern applications tend to have multiple screens (either multiple windows open, or multiple screens in -memory that the user switches between). This model does not handle screen coordination terribly well.
- A single monolithic model should usually be split into multiple models, to reflect specialized data needs of each screen.
There have been a number of variant versions of MVC (MVP, MVVM, MVI). Let’s discuss a very popular specialization: MVVM.
Model-View-ViewModel (MVVM)
Model-View-ViewModel was invented by Ken Cooper and Ted Peters in 2005. Based on Martin Fowler’s Presentation Model, it was intended to simplify event-driven programming and user interfaces in C#/.NET.
MVVM suggests two major changes from MVC:
- MVVM removes the Controller class, and
- MVVM adds a data container class named the
ViewModel, that sits between theViewandModel.
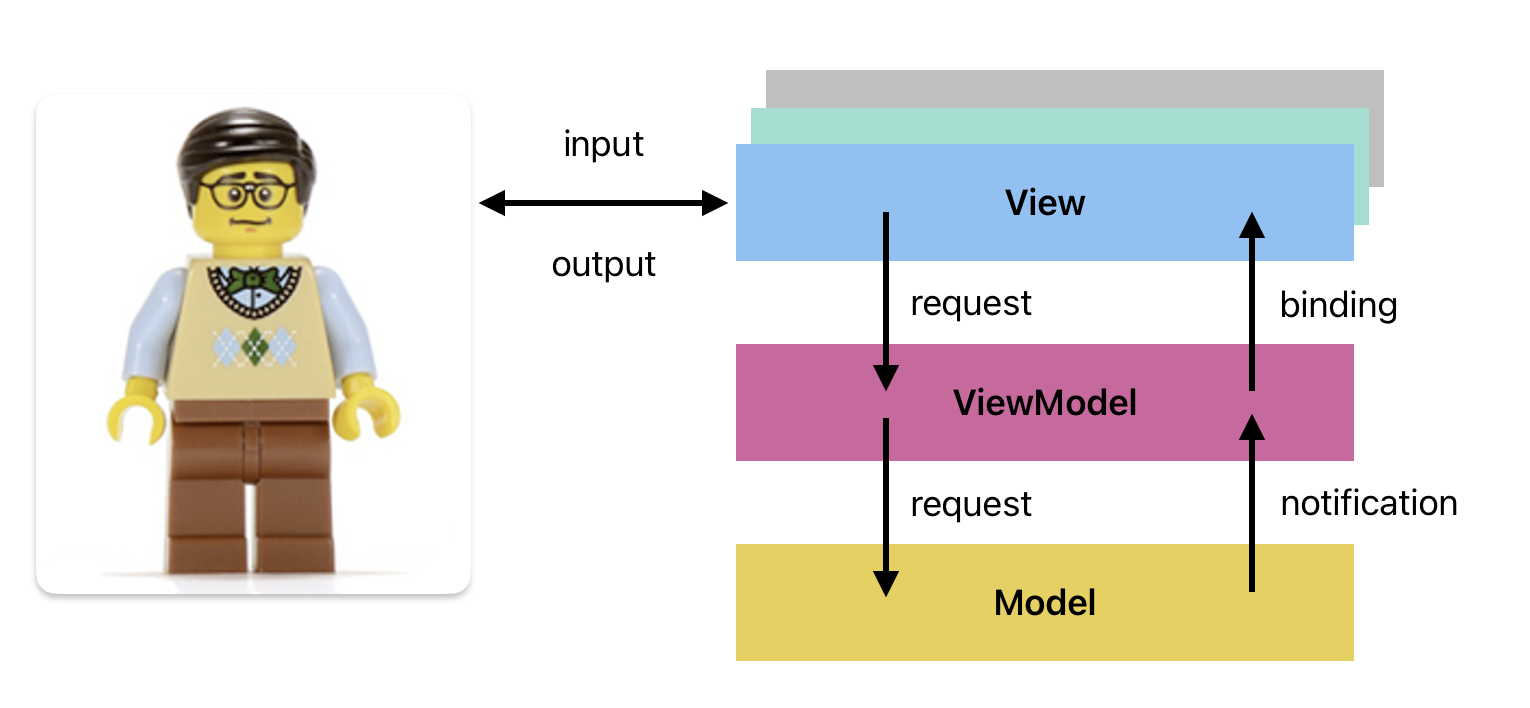
This reduces our application to the following components:
Model: As with MVC, the Model is the primary Domain object, holding the application state.View: The structure, layout and presentation of what is on-screen. With modern toolkits, the View handles both input and output i.e. the complete user experience.ViewModel: A component that stores data that is relevant to the View to which it is associated. This may be a simple subset of Model data, but is more often a reinterpretation of that data in a way that makes sense to the View e.g., dollar amounts in USD in the Model may be reflected in a local currently in the ViewModel.
One interesting trend that works in favor of MVVM is the idea of reactive programming, where changes in one component are automatically published to other interested components. MVVM is often implemented in a way where we can use a binding mechanism to map variables in the ViewModel directly to widgets in the View, so that updating one directly updates the other.
What is the benefit of a ViewModel?
- We will often want to pull “raw” data from the Model and modify it before displaying it in a View e.g., currency that is stored in USD but should be displayed using a local currency.
- We sometimes want to make local changes to data, but not push them automatically to the Model e.g., undo-redo where you don’t persist the changes until the user clicks a Save button.
MVVM recommends that you have one ViewModel for each View, and that ViewModel manages all data for that View. It looks something like this:
classDiagram
ISubscriber "1" <|.. "1" ViewModel
IPublisher <|.. Model
ISubscriber "*" <.. "*" IPublisher
View "1" --> "1" ViewModel
View "1" <-- "1" ViewModel
ViewModel "*" <.. "*" Model
class View {
-Model model
-ViewModel viewModel
}
class ISubscriber {
<<Interface>>
+update()
}
class ViewModel {
-View view
-Model model
+update()
}
class IPublisher {
<<Interface>>
-List~Subscriber~ subscribers
+notify()
}
class Model {
+var data
+subscribe(ISubscriber)
+unsubscribe(ISubscriber)
}
MVVM is common in modern languages and toolkits, but it’s just one variant of MVC. There are many other variants (e.g. Model-View-ViewController) which deviate from “standard” MVC, usually in an attempt to solve a particular problem in a more elegant fashion. They all build on the same observer foundation.
MVVM is an elegant solution to our first requirement: it handles the interaction cycle pretty well!
However it doesn’t handle our second requirement: multiple data sources. How could MVVM handle inputs from multiple sources? What if you needed to access other resources like files, databases, APIs. How do you integrate these?
Layered architecture
The second main pattern that we will see if the layered architecture. A layered architecture divides your application into slices, each with its own area of responsibilty.
Like MVC and MVVM, it’s primary concern is separation of concerns between the User-interface and the Model layers.
There are many variations to a layered architecture, with different names for each layer. The critical part of this pattern isn’t the number of layers, or even the names of the layers; it’s the way that the layers communicate, how control and data is passed between layers.
We’ll use the following four layers:
User Interface: This is the same layer we introduced in the MVVM section above. (In fact, we will implement it using View and ViewModel classes, since that was such a useful idea).Domain: Classes that model your particular problem/user stories. These are often your data classes or representational classes that are specific to your application. e.g., if you are building a Recipe tracking application, your Domain layer would include classes like Recipe, RecipeList, RecipeFolder and so on. Domain-specific logic typically goes here.Model: This is the same layer that we introduced in MVVM, that stores the primary application state. It’s the “source of truth” for your application.Service: This is an API or interface to a system that will retrieve data for our application. This could be called a Database layer or Repository layer in other layered architectures. I prefer the termService layerbecause in modern applications, we’re as likely to be pulling in data from a remote API as we are from a remote database. Fundamentally, there are data providers for the Model.
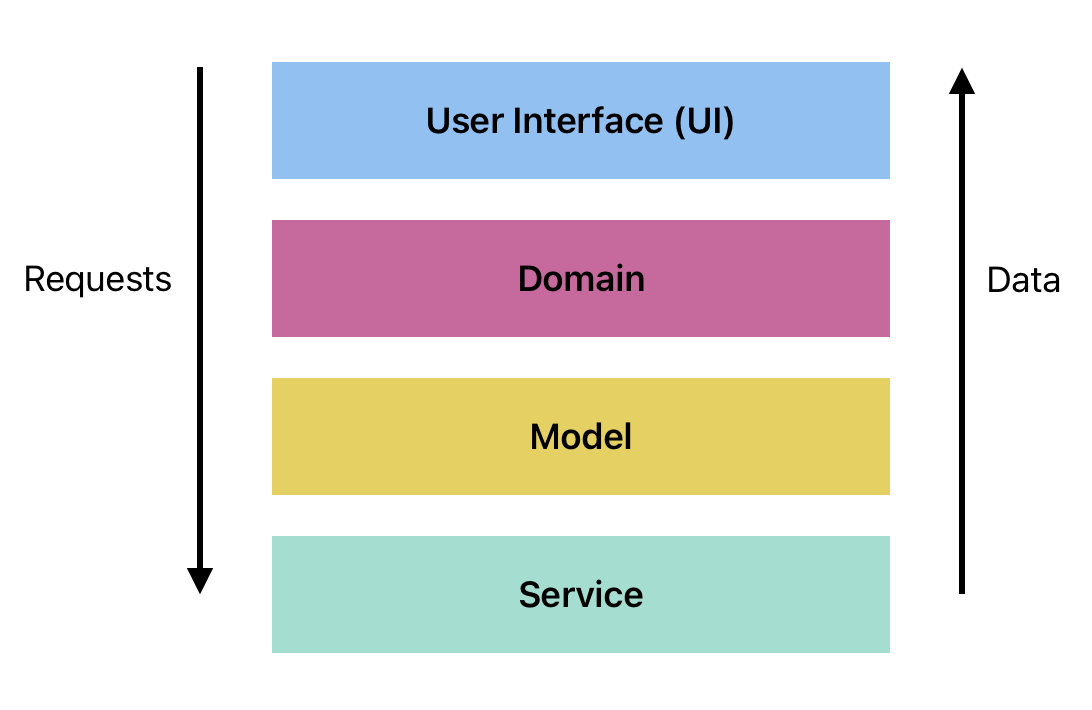
The characteristics of this approach:
- Each layer contains one or more classes with similar functionality. Classes can freely communicate within their layer.
- Dependencies between layers are top-down. i.e., the UI has a reference to the Domain layer, and can pass requests down to it; the Domain layer in turn can only communicate down to the Model layer. Layers call “down” to perform some service.
- As a rule, requests (messages) flow down, and notifications (data) flow back up.
For example, if the user interacts with the User Interface layer to direct it to perform some action, a message is generated that represents that action. This message flows down through each successive layer, triggering behaviour in each layers. In response, data flows back up. e.g., imagine clicking on a button to request details on a customer record; a message would be sent to the Domain layer, which would work a query directing the Model to get data, and return it to the User Interface layer.
Let’s discuss the layers and how they relate to one another.
Layers
User Interface (UI) layer
The User Interface, or Presentation layer, is the part of your application that the user interacts with (i.e. the “person” side of the interaction diagram). This is responsible for handling user input, and expressing output. This layer can be quite complex since it handles IO for all devices (keyboards, mice, touchpads) as well as the UI that the user interacts with (console, graphical).
Graphical interfaces typically consist of multiple screens, each with their own interaction support and visual representation. The layer itself will commonly include a large number of specialized classes (which we will discuss further below).
Domain layer
The Domain layer describes the application logic for our program. e.g., rules for managing customer data, or bank transactions, or how to combine ingredients in a recipe, or whatever else is needed. It serves as an intermediate layer between the raw data (e.g., records from the Model) and how that data is presented (e.g., screens in the UI layer).
Small applications sometime omit the domain layer (so that the architecture simply consists of user-interface and model layers). In this course, we will keep the domain layer; it makes SoC and testing much easier to achieve, even if our Domain layer just ends up being a few data classes.
Model layer
The actual application data being stored in memory, is often pulled from different sources e.g., bank transactions fetched from a database, user profile information stored in a preferences file. The model is meant to be the primary representation of the data in our application (the “single source of truth” in our application). The model is ultimately responsible for consolidation and presenting data to the rest of the application.
Service layer
This is a representation of the storage mechanism that actually retrieves or persists data. This can take many forms, from files on a file-system, to records in a relational database, or a bytestream from a DVD or some form of storage. The model interacts directly with service layer to fetch and manage this data and present it to other layers.
Sometimes, in simple architectures, this layer will not be shown, and is instead collapsed into the Model layer. In this course (and in general), we prefer to keep it as a separate layer, since it’s not unusual to have multiple forms of storage at-play in our application e.g., imagine a Twitter client that pulls tweets from a remote API (one source), uses a local data file to store application preferences (a second source) and a remote database to store account information (a third source).
Data is passed back up the layers through dependency inversion: the use of interfaces keeps layers isolated.
Dependencies (down)
What do we mean by dependencies being directed down?
Imagine that we have simple classes for a CustomerView (e.g., a customer record screen in the user interface layer) and a CustomerModel (e.g., a class in the model layer that stores customer information). Dependencies being directed down means that the View classes can reference the Model classes directly, but not the other way around.
In the example below, we show part of an application (simplified, using the layers as class names for illustration). The UI layer can use (depend) on the Domain layer and any classes it contains. This is a one-way dependency; the Domain classes are not allowed to have any reference back to the UI layer.
classDiagram
UI "*" --> "*" Domain
Domain "*" --> "1" Model
Model "1" --> "*" Service
class UI {
data: Data
+display(data)
}
class Domain {
data: Data
+sort(data)
}
class Model {
data: Data
+add(data)
+del(data)
}
class Service {
data: Data
+load() data
+save(data)
}
Notifications (up)
What do we mean by data being directed up?
The Model needs to have some way of notifying the View that the data has changed, without a direct reference to that view (“loose coupling”, remember?).
The Model doesn’t have a directly reference to the View, so what do we do? We use a loose coupling mechanism to send messages to the View. This is effectively the Observer design pattern, where the View (ISubscriber interface) is registers itself with the Model (IPublisher). The Model publishes changes to all registered Views when they occur.
This mechanism works for any data change in the model e.g., a system event causes the data to change, or data changes in the database, or the user changes data in one window causing a second window to update).
Here’s a simple example with notifications using the Publisher/Subscriber interfaces.
classDiagram
Subscriber "1" <|.. "1" UI
Publisher <|.. Model
Subscriber "*" <-- "*" Publisher
class UI {
data: Data
+display(data)
}
class Subscriber {
<<Interface>>
+update()
}
class Publisher {
<<Interface>>
List~Subscriber~ subscribers
-notify()
}
class Model {
data: Data
+add(data)
+del(data)
+subscribe(Subscriber)
+unsubscribe(Subscriber)
}
Abstraction
Finally, one important piece of this approach is the use of Interfaces to promote loose coupling. By describing component relationships in terms of behaviours we have the flexibility to swap in new implementations at any time (abstractions not concretions).
This is especially important for
Subscribers: we want any form of user interface to be able to receive notifications, not just GUI screens. e.g., we might send output to a voice dictation system, or a printer. I once worked on a project where the build output would trigger a lava lamp to light up (green for a passed build, red for a failed one!).Publishers: we want the flexibility of multiple models. We may not do this in production, but we can certainly do it when testing.Services: finally, we want to be able to request data and save data to a variety of services without knowing the implementation details. e.g., your model shouldn’t know the details of how to save to a SQL database, it should rely on an abstraction that exposes save behaviour. This let us swap databases, or even just save data to a file for testing instead of our remote DB.
Implementation
Full diagram
Here’s the full diagram, with all of the required classes for a layered architecture (including View/ViewModels and Services).
classDiagram
UI "1" --> "1" ViewModel
ViewModel "1" --> "*" Domain
Domain "*" --> "1" Model
Model "1" --> "*" Servicer
Subscriber "1" <|.. "1" ViewModel
Publisher <|.. Model
Subscriber "*" <-- "*" Publisher
Servicer <|.. Service
class UI {
data: Data
+display(data)
}
class ViewModel {
model: Model
+update()
}
class Domain {
data: Data
+sort(data)
}
class Subscriber {
<<Interface>>
+update()
}
class Publisher {
<<Interface>>
List~Subscriber~ subscribers
-notify()
}
class Servicer {
<<Interface>>
data: Data
+load()
+save()
}
class Model {
data: Data
+add(data)
+del(data)
+subscribe(Subscriber)
+unsubscribe(Subscriber)
}
class Service {
data: Data
+load()
+save()
}
Sample code
The diagrams in the previous section above are treating each layer as if it was a single class named for that layer e.g., a UI class, a Domain class and so on. This is almost never going to be true; layers will usually consists of a number of related classes, each responsible for different parts of that layer.
Let’s imagine a simple application with a single View, ViewModel and Model. Here’s what the code would look like.
In our Main class, we instantiate classes and use dependency injection to connect our class instances. These should mirror the relationships on our diagram above.
// main class
class Main {
val model = Model()
val viewModel = ViewModel(model)
val view = View(viewModel)
model.add(viewModel)
}
The Subscriber interface is an abstraction for any class that wants to be notified of model changes. Any class can act like a view as long as it supports the appropriate method to allow notifications from the model. In this case, our ViewModel is the Subscriber. It will be subscribed for Model updates, and will take care of notifying its associated View as needed.
// UI classes
interface Subscriber {
fun update()
}
class View(val viewModel: ViewModel) {
// some user interface class that relies in the viewModel for its state
// assume it can pull state from the viewModel and display it
}
class ViewModel(val model: Model) : Subscriber {
override fun update() {
// this method is called by the Publisher (aka Model) when data updates
// fetch data from model when the model updates
}
}
The Publisher (aka Model) maintains a list of all Subscribers (aka ViewModels), and notifies each one of them when its state changes. The Publisher has no control over how they react; each Subscriber must decide what to do with the update basd on whether the data is relevant to them. i.e., they might ignore the notification if it’s data they don’t use, or they might choose to fetch updated data from the Model.
In the code below, the Publisher is an abstract class (vs. an interface) so that we can add default implementation code for managing the Subscriber list.
abstract class Publisher {
val views: List<Subscriber> = emptyList()
fun addView(view: Subscriber) {
views.add(view)
}
fun update() {
for (view : views) {
view.update()
}
}
}
class Model {
fun fetchData() {
// do something that causes data to change
update() // notify subscribers
}
}
Benefits
Layering our architecture really helps to address our earlier goals (reducing coupling, setting the right level of abstraction). Additionally, it provides these other specific benefits:
- Independent of frameworks. The architecture does not depend on a particular set of libraries for its functionality. This allows you to use such frameworks as tools, rather than forcing you to cram your system into their limited constraints.
- Testable. The business rules can be tested without the UI, database, web server, or any other external element.
- Independent of the UI. The UI can change easily, without changing the rest of the system. A web UI could be replaced with a console UI, for example, without changing the business rules.
- Independent of the database. You can swap out Oracle or SQL Server for Mongo, BigTable, CouchDB, or something else. Your business rules are not bound to the database.